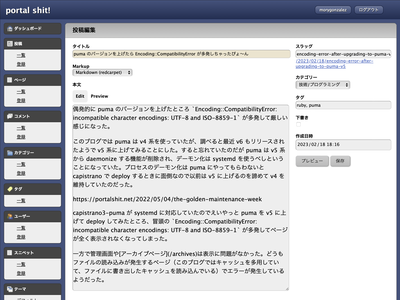
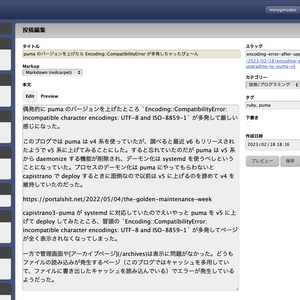
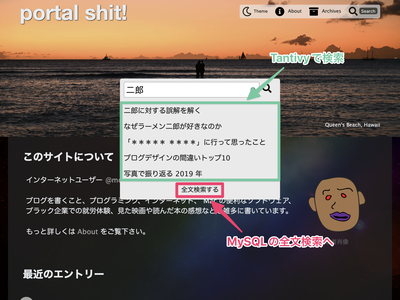
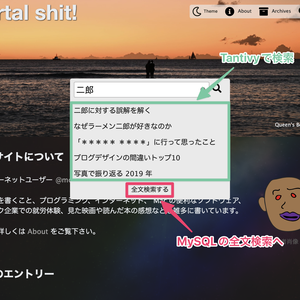
ショートカットキーで検索窓を開けるようにし、矢印キーで検索結果を選択できるようにした
Mac の定番ランチャー、 Alfred のような検索 UI が好きだ。こういう UI で検索できるソフトウェアやウェブサイトがあると気持ちいい。自分のブログにモーダルウィンドウの検索を追加したときも Alfred みたいにしたいと思いながら作った。 ブログに Alfred 風のインクリメンタルサーチを実装 グローバルナビゲーション(右上の白い領域)内の検索ボタンを押したら Alfred 風のモーダル検索フォームが開いて、そこにキーワードを入力するとインクリメンタルサーチが実行されて逐次検索結果の記......