Homebrew で入れた SQLite で load_extension() が動かなくなっていた。
どうも以前は --enable-loadable-extensions でビルドできていたらしいが、 Homebrew 全体でオプション指定をできなくする変更が 4 年前にあったみたいだ。
オプション指定できるのは UX として良くない(ビルド済みのバイナリをダウンロードできない)し、オプション指定を Homebrew のチームでテストしていないからだそう。
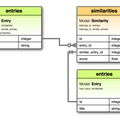
TF-IDF で関連記事を表示する機能は SQLite の拡張に依存していたので、最近 Homebrew で入れた SQLite だと機能が動かなくなってしまった(エラーが発生する)。
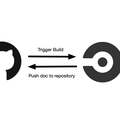
対策としては自分で SQLite をビルドするしかない。 Mac でそれやるのは面倒なのでこういうのは全部 Docker でやることにした。
Homebrew のウリはビルド済みのバイナリをサクッとダウンロードできてローカルでビルド不要なところではあると思うが、ちょっと凝ったことをしようとするとソースコードをダウンロードしてきて手元でビルドしないといけなくなってしまった。依存パッケージをまとめてインストールできてたことも便利だったんだけど、カスタムインストールをしたいときは昔みたいに依存関係を自分で調べて都度都度インストールしていかないといけなくなった。開発チームの考えもわからなくはないがちょっと残念だ。
ちなみに Homebrew のリポジトリ( homebrew-core )の過去のコミットログを調べるのがめっちゃ大変だった。 tig Formula/sqlite.rb しても 3 分くらい反応がなかった。 git log -Sextension Formula/sqlite.rb してそれっぽいコミットのハッシュ値を見つけて GitHub で検索して何とか上記の Pull Request と Issue に辿り着いた。超巨大なプロジェクトのソースコード管理は Git でやると大変そうだ。







 転職して一年が経った。まだまだ課題はあるが、職業エンジニアになってからでは飛躍的に成長できた一年だったと思う。大きかったのはインフラ関連の技術の習得で、 Docker での開発環境構築、 CircleCI を活用したビルドとデプロイの仕組みの構築、 Terraform を使ったインフラのコード化、オートスケールの仕組みの構築など、これまで担ってこなかったタスクを担当することができ非常に得るものが大きかった。これまで在籍してきた職場ではこれらのタスクに関して自分よりも圧倒的に優れた人たちがいたので自分が手を出せるような隙がなかった。小さなスタートアップは慢性的に人手が足りていないので『隙』は無数にあり、これまでのキャリアで担当できなかったタスクに手を出しやすい。自分にはまだまだ技術的な伸び代があることがわかり、 35 歳定年説なんてちゃんちゃらおかしいわ、と思えるほどにこれからも全然エンジニアとしてやっていけそうな気がしている。とはいえあんまり調子こいてると足をすくわれると思うので、自信を持ちつつも尊大にならず良い感じに余生を過ごしたい。
転職して一年が経った。まだまだ課題はあるが、職業エンジニアになってからでは飛躍的に成長できた一年だったと思う。大きかったのはインフラ関連の技術の習得で、 Docker での開発環境構築、 CircleCI を活用したビルドとデプロイの仕組みの構築、 Terraform を使ったインフラのコード化、オートスケールの仕組みの構築など、これまで担ってこなかったタスクを担当することができ非常に得るものが大きかった。これまで在籍してきた職場ではこれらのタスクに関して自分よりも圧倒的に優れた人たちがいたので自分が手を出せるような隙がなかった。小さなスタートアップは慢性的に人手が足りていないので『隙』は無数にあり、これまでのキャリアで担当できなかったタスクに手を出しやすい。自分にはまだまだ技術的な伸び代があることがわかり、 35 歳定年説なんてちゃんちゃらおかしいわ、と思えるほどにこれからも全然エンジニアとしてやっていけそうな気がしている。とはいえあんまり調子こいてると足をすくわれると思うので、自信を持ちつつも尊大にならず良い感じに余生を過ごしたい。



