以前、以下の記事でこのウェブサイトへのアクセス元 User Agent について書いた。

そのとき Hatena::Russia::Crawler というのが謎だということを書いた。最近のアクセスログを見ても相変わらずこの User Agent からのアクセスが多い。またアクセス頻度も高く、同一の URL に対して何度もアクセスしている。
これはやはりはてなの名を騙った怪しいクローラーなのではないかと思い調べてみた。
まず Hatena::Russia::Crawler という User Agent からのアクセスの IP アドレスを調べてみたところ以下だった。
cat log/access.log | grep 'useragent:Hatena::Russia::Crawler/0.01' | cut -f2 | sort | uniq -c | sort -nr
434 remote_addr:52.68.0.227
419 remote_addr:54.249.85.140
417 remote_addr:54.92.97.59
379 remote_addr:54.250.227.185whois してみると AWS で運用されているものであることがわかるが、はてなのものかは断定できない。
もしこの IP からはてなブックマークやはてなアンテナなどの User Agent でのアクセスもあれば Hatena::Russia::Crawler ははてなのクローラーであると断定できるだろう。ということで調べてみたところこんな感じだった。
zcat -f log/access.log* | grep -E 'remote_addr:(52\.68\.0\.227|54\.249\.85\.140|54\.92\.97\.59|54\.250\.227\.185)' | cut -f13,2 | sort | uniq -c | sort -nr
16687 remote_addr:54.250.227.185 useragent:Hatena::Russia::Crawler/0.01
16448 remote_addr:54.92.97.59 useragent:Hatena::Russia::Crawler/0.01
16370 remote_addr:54.249.85.140 useragent:Hatena::Russia::Crawler/0.01
16272 remote_addr:52.68.0.227 useragent:Hatena::Russia::Crawler/0.01
73 remote_addr:54.249.85.140 useragent:HatenaBookmark/4.0 (Hatena::Bookmark; Scissors)
60 remote_addr:54.250.227.185 useragent:HatenaBookmark/4.0 (Hatena::Bookmark; Scissors)
56 remote_addr:52.68.0.227 useragent:HatenaBookmark/4.0 (Hatena::Bookmark; Scissors)
50 remote_addr:54.92.97.59 useragent:HatenaBookmark/4.0 (Hatena::Bookmark; Scissors)
31 remote_addr:54.92.97.59 useragent:Hatena::Fetcher/0.01 (master) Furl/3.13
31 remote_addr:54.250.227.185 useragent:Hatena::Fetcher/0.01 (master) Furl/3.13
31 remote_addr:54.249.85.140 useragent:Hatena::Fetcher/0.01 (master) Furl/3.13
26 remote_addr:52.68.0.227 useragent:Hatena::Fetcher/0.01 (master) Furl/3.13
19 remote_addr:54.92.97.59 useragent:Hatena::Scissors/0.01
19 remote_addr:54.250.227.185 useragent:Hatena::Scissors/0.01
16 remote_addr:52.68.0.227 useragent:Hatena::Scissors/0.01
9 remote_addr:54.249.85.140 useragent:Hatena::Scissors/0.01なんと、 IP アドレスで検索してはてなのその他のクローラーもヒットしてしまった。つまり Hatena::Russia::Crawler ははてなのクローラーということだ。
ただしググっても一切情報が出てこない。 Hatena::Russia::Crawler で検索してトップヒットするのは自分のブログだ。
改めて Hatena::Russia::Crawler による直近 30 日間のアクセス状況を調べてみるとこんな感じだ。
zcat -f log/access.log* | grep 'useragent:Hatena::Russia::Crawler/0.01' | cut -f5 | sort | uniq -c | sort -nr
15697 request_uri:/index.atom
9913 request_uri:/2022/04/20/integrate-charts-category-with-select-boxs
9373 request_uri:/2022/05/04/reputation-and-interpretation
8422 request_uri:/2022/05/11/fly-to-kamikochi-from-fukuoka
7716 request_uri:/2022/05/16/using-tantivy-over-tantiny
5906 request_uri:/2022/04/17/quit-using-hey
5139 request_uri:/2021/12/29/thoughts-on-manga-subscription
1308 request_uri:/2021/12/13/keep-a-stack-books-whether-reading-them-or-not
787 request_uri:/2022/06/23/each-entry-title-should-be-marked-up-with-h1
741 request_uri:/2021/12/13/keep-stack-books-whether-reading-them-or-not
456 request_uri:/2022/06/24/if-you-feel-apple-musics-recommendation-is-awful
100 request_uri:/2022/06/14/thoughts-on-hatena-bookmark
46 request_uri:/2015/12/07/thoughts-on-rural-life
46 request_uri:/2015/12/02/thoughts-on-t-on-t
46 request_uri:/2015/12/02/thoughts-on-christmas-song
45 request_uri:/2019/12/02/stop-drinking-outside-frequently
16 request_uri:/2020/11/08/where-i-went-in-2019
11 request_uri:/2015/12/05/omm-writer-music-is-nice-to-listen-to-while-writing
5 request_uri:/2022/05/04/the-golden-maintenance-week
2 request_uri:/2022/06/24/
2 request_uri:/2022/06/24index.atom はフィードの URL なので除外するとして、特定の記事に対して数千回もアクセスがある。 30 日間で 9000 回ということは一日あたり 300 回だ。 1 時間あたり 12.5 回である。何のためにこんなに高頻度でクローリングしているのだろうか。
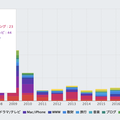
とここまで調べたところほかの Bot 系アクセスはどうなのかと改めて User Agent 毎のアクセス数を調べてみたらこんな感じだった。
zcat -f log/access.log* | cut -f13 | sort | uniq -c | sort -nr | head -10
124894 useragent:Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)
65794 useragent:Hatena::Russia::Crawler/0.01
58274 useragent:Ruby
31493 useragent:Mozilla/5.0 (iPhone; CPU iPhone OS 15_4_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.4 Mobile/15E148 Safari/604.1
29454 useragent:Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)
21492 useragent:Tiny Tiny RSS/21.11-7cfc30a (https://tt-rss.org/)
20351 useragent:Slackbot 1.0 (+https://api.slack.com/robots)
18765 useragent:Mozilla/5.0 (compatible; SemrushBot/7~bl; +http://www.semrush.com/bot.html)
18395 useragent:Mozilla/5.0 (compatible; MJ12bot/v1.4.8; http://mj12bot.com/)
17942 useragent:Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)bingbot からのアクセスの方が Hatena::Russia::Crawler からのアクセスの 2 倍近くあった。ただし bingbot は検索エンジンのクローラーらしく、サイト全体をまんべんなくクローリングするような挙動で、特定の URL に一ヶ月間で数千回アクセスするような感じではない。
zcat -f log/access.log* | grep 'useragent:Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)' | cut -f5 | sort | uniq -c | sort -nr | head -25
571 request_uri:/robots.txt
352 request_uri:/
205 request_uri:/category/misc
160 request_uri:/2007/01/13/732
156 request_uri:/2005/10/28/129
150 request_uri:/2009/03/23/1010
148 request_uri:/category/music
146 request_uri:/archives
144 request_uri:/category/www
143 request_uri:/2016/07/
143 request_uri:/2009/08/31/1074
139 request_uri:/2010/07/05/1140
138 request_uri:/category/photo
138 request_uri:/2009/02/
137 request_uri:/2006/09/09/658
136 request_uri:/tags/netatmo
136 request_uri:/2010/07/17/1145
136 request_uri:/2006/07/23/611
135 request_uri:/2014/03/
134 request_uri:/?page=32
134 request_uri:/2007/02/09/747
133 request_uri:/category/shopping
133 request_uri:/2021/07/26/how-to-get-to-kamikochi-from-fukuoka
133 request_uri:/2011/11/03/finally-got-hhkpro2
132 request_uri:/2006/01/Hatena::Russia::Crawler は同一 URL に数千回もアクセスして何をしているのだろう? 謎は深まるばかりだ。