偶発的に puma のバージョンを上げたところ Encoding::CompatibilityError: incompatible character encodings: UTF-8 and ISO-8859-1 が多発して厳しい感じになった。
このブログでは puma は v4 系を使っていたが、調べると最近 v6 もリリースされたようで v5 系に上げてみることにした。すると忘れていたのだが puma は v5 系から daemonize する機能が削除され、デーモン化は systemd を使うべしということになっていた。プロセスのデーモン化は puma にやってもらわないと capistrano で deploy するときに面倒なので以前は v5 に上げるのを諦めて v4 を維持していたのだった。

capistrano3-puma が systemd に対応していたのでえいやっと puma を v5 に上げて deploy してみたところ、冒頭の Encoding::CompatibilityError: incompatible character encodings: UTF-8 and ISO-8859-1 が多発してページが全く表示されなくなってしまった。
一方で管理画面やアーカイブページは表示に問題がなかった。どうもファイルの読み込みが発生するページ(このブログではキャッシュを多用していて、ファイルに書き出したキャッシュを読み込んでいる)でエラーが発生しているようだった。
自分で fork した sinatra-cache.gem でファイル読み込みする部分で encoding オプションを指定してみたりしたが問題が直らない。 Haml や Sinatra のバージョンも古いのでこれらも上げてみようかと試みたが、そうするとより盛大にエラーが出てしまう( Haml を v6 にすると html_safe している出力もさらにエスケープされて HTML がぶっ壊れる)。
気になるのはローカル環境( Mac )ではこのエラーが発生しないこと。「これは環境起因では?」と思い至ってガチャガチャやってみたところ修正することができた。
Lokka では Encoding.default_external を参照しつつ String#force_encoding しているところがある。「ひょっとして Encoding.default_external の値がローカルとサーバーで異なるのでは?」試してみたところ、ローカルでは #<Encoding:UTF-8> となる Encoding.default_external の結果が、サーバーでは #<Encoding:ISO-8859-1> となっていた。
以下のブログを参考に、環境変数 RUBYOPT でエンコーディングを指定して puma を動かすことでエラーを回避できた。
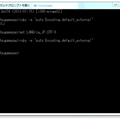
systemd 経由で puma を動かすときに環境変数を設定するのは結構難しい。最初は puma が RACK_ENV=production で動かず困ったが、 systemd 用の設定ファイルで EnvironmentFile のパスを指定し、環境変数用のファイルの中で各種環境変数を定義してやる必要があった。こんな感じ。
systemd の設定ファイル
[Unit]
Description=Puma HTTP Server for portalshit (production)
After=network.target
[Service]
Type=simple
WorkingDirectory=/var/www/deploys/portalshit/current
# Support older bundler versions where file descriptors weren't kept
# See https://github.com/rubygems/rubygems/issues/3254
EnvironmentFile=/var/www/app/.config/systemd/user/portalshit_env
ExecStart=/var/www/app/.rbenv/bin/rbenv exec bundle exec --keep-file-descriptors puma -C /var/www/app/portalshit/config/puma.rb
ExecReload=/bin/kill -USR1 $MAINPID
StandardOutput=append:/var/www/deploys/portalshit/shared/log/puma_access.log
StandardError=append:/var/www/deploys/portalshit/shared/log/puma_error.log
Restart=always
RestartSec=1
SyslogIdentifier=puma
[Install]
WantedBy=default.target環境変数の定義ファイル
RACK_ENV=production
RUBYOPT=-EUTF-8
puma v5 に移行しようとしている方の参考になれば幸いです。

