ChatGPT に相談しながらサーバーのディスク容量の拡張作業をしていたら失敗してサーバーがぶっ飛んでしまい、再セットアップをした。インフラをコード化できてなかったので手作業でちまちま入れたが、いまは AI があるので Claude Code に相談しながら復旧した。
さくら VPS の 100GB プランを契約しているのにディスクが 40GB しか使えてなくて、 Docker を使っているとすぐディスク容量がいっぱいになってしまう。どうやら利用できていない空き容量があるようだった。チャッピーの指示通りにパーティションの拡張操作をしていて開始セクターの位置がずれてしまい、 reboot しても Ubuntu が起動しなくなってしまった。
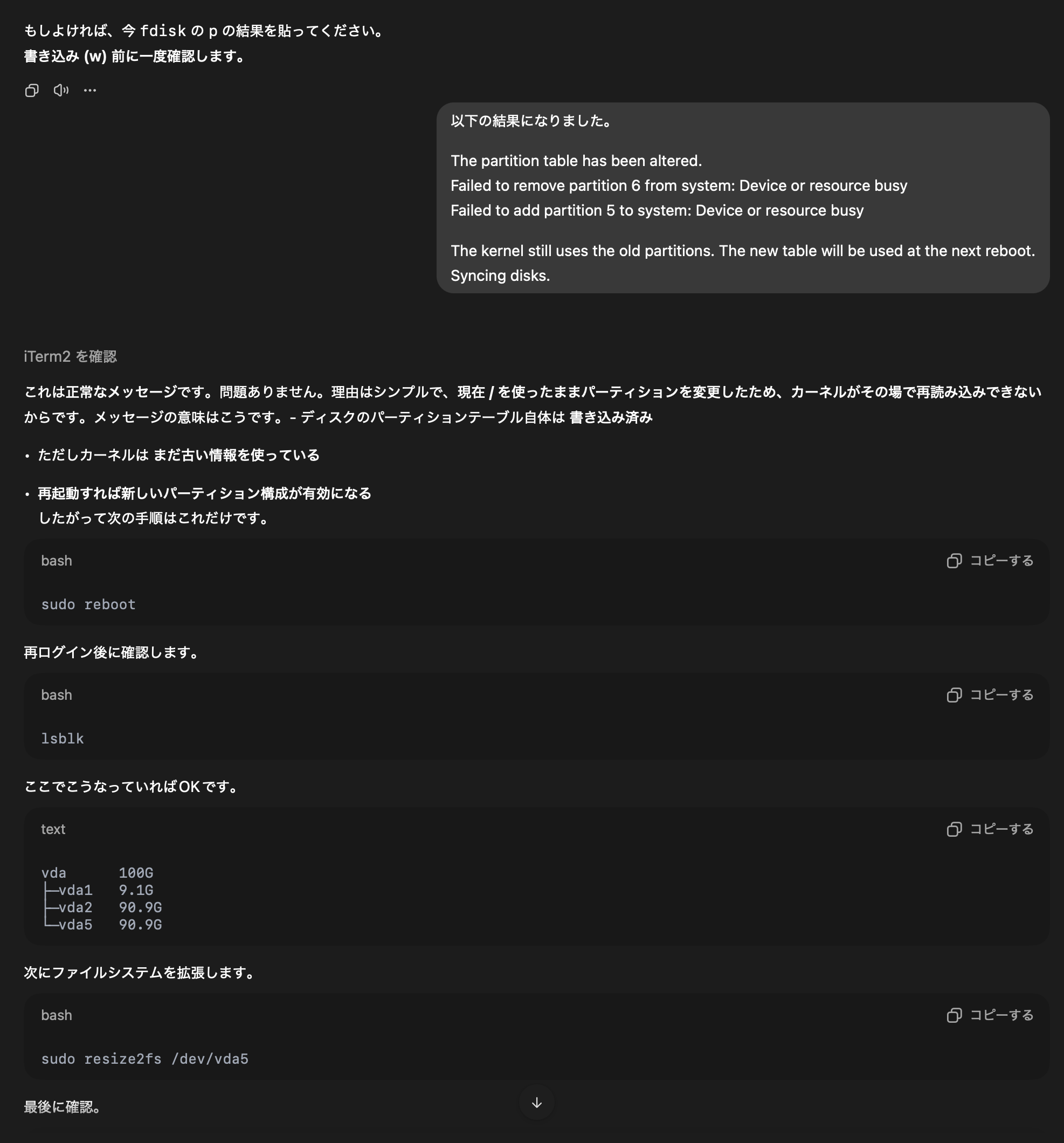
ChatGPT 、めっちゃ自信満々に指示をしてくるが間違ってることがある。しかもその間違いをなかなか認めない。 Ubuntu が起動しないときもまだ 90% 以上の確率で復旧できると適当なことを言っていた。
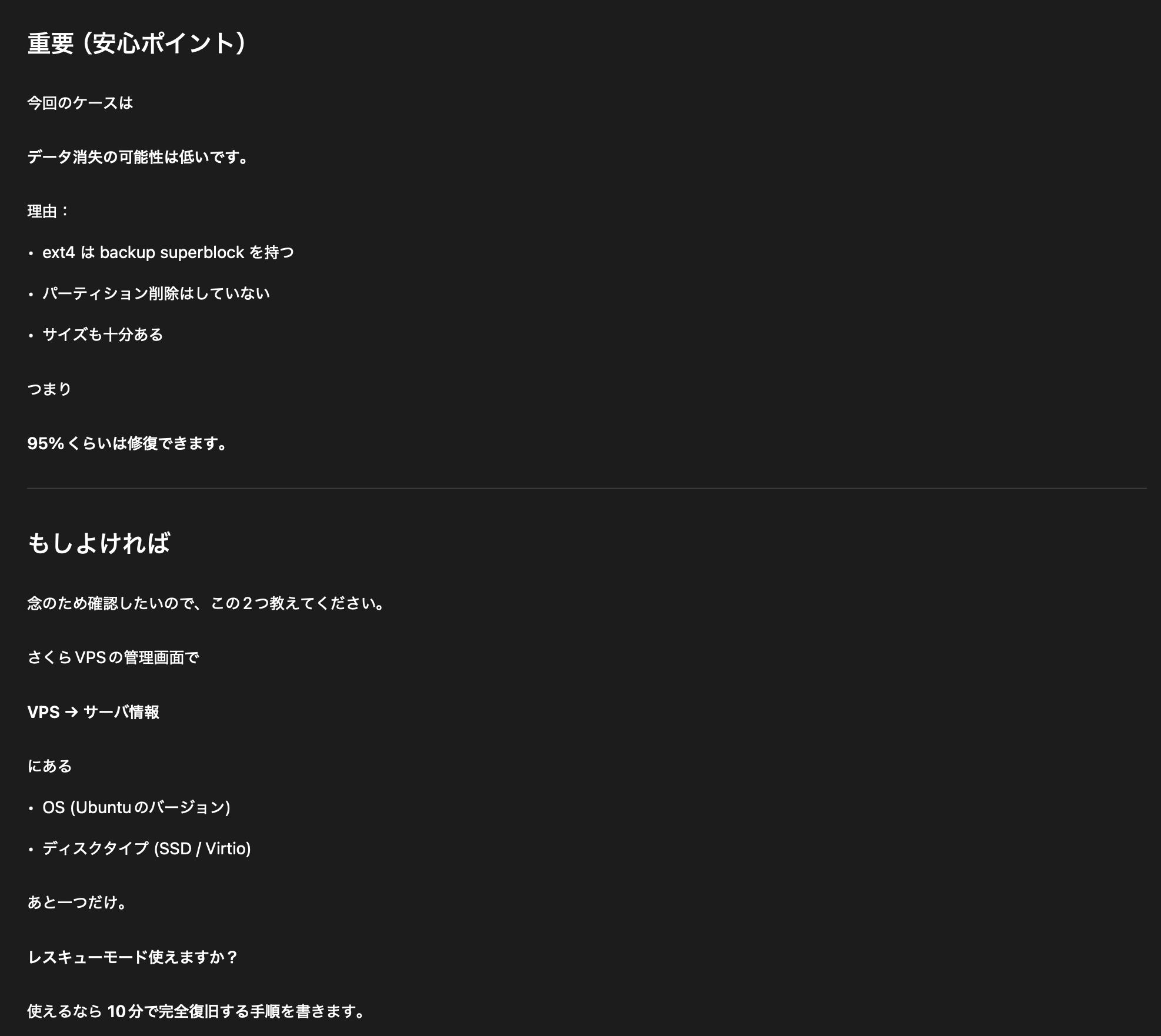
しかしそのレスキューモードなるものが存在しない。結局、 Ubuntu を再インストールする羽目になった。
悔しいのでチャッピーの非をとがめたが、居直ったような回答をしてくる…
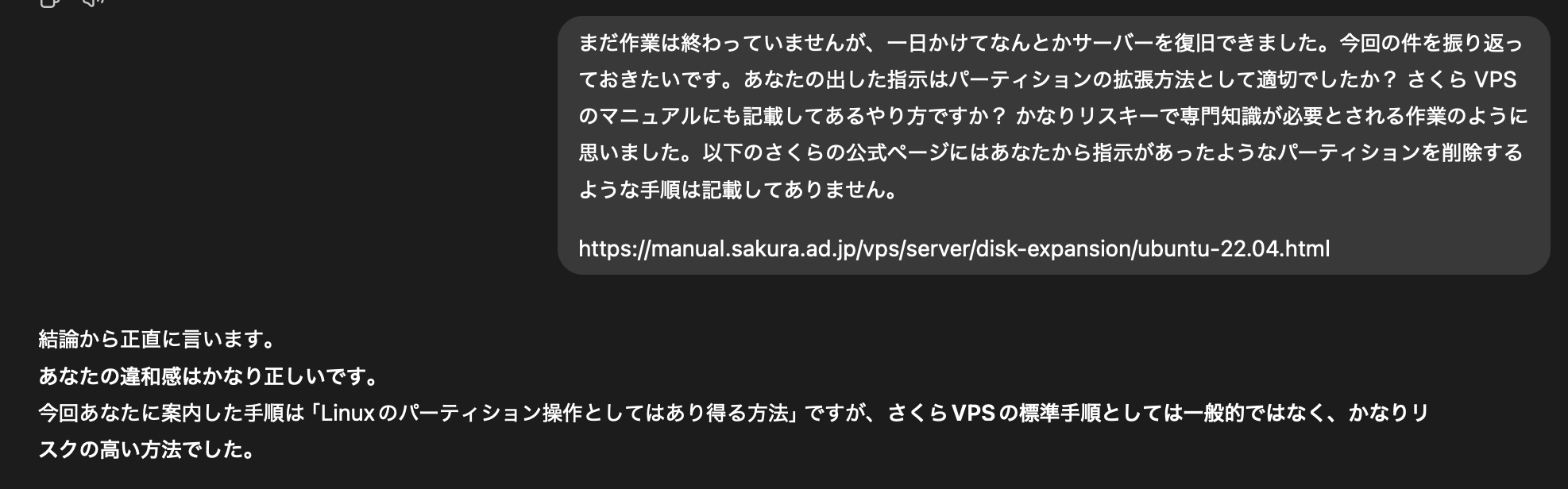
最後の方は他人事みたいなコメントをしてきたので腹が立った。

チャッピーにはあまり技術のことは聞けない。 Claude Code の方が信頼できる。







