ブログ過去記事の閲覧 UI にはこだわりがある。これまで何度か記事を書いた。
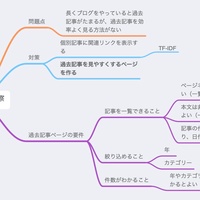
このブログの維持管理で一番時間を割いているのが Archives ページだ。しかしアクセスログを見ると自分以外はほとんど利用していない。完全に自己満なのだが、過去の自分を振り返ることができてとても自分には有意義なページだ。
過去記事を振り返るときには検索をしたくなる。タイトルのみであればページ内検索で探せるが、やっぱり本文込みで検索したい。 Lokka の検索はあるが、検索結果ページは 7 件ずつ(この値はカスタマイズできる)表示で全文表示される。自分は検索キーワードに関する記事が存在するか知りたい訳ではない。著者なのでキーワードに関連する記事があるかないかくらいわかってる。じゃなくて過去の自分がいつ頃どの密度でそのトピックについて書いていたかを知りたいのだ。
タグやカテゴリーで絞り込む手もある。しかしカテゴリーやタグは理想的な分類ではない。二つのカテゴリーを横断するような記事があるし、タグは設定し忘れていることが多い。全文検索が一番頼りになる。
SQL で全文検索的なことをやろうとするとパフォーマンスが良くないだろう。やっぱり全文検索システムが欲しい。
Tantivy と Tantiny
とはいえ、個人のブログで全文検索エンジンを導入するのはしんどい。確かに Apache Solr や Elasticsearch を個人ブログに入れるのはきつい。もっと手軽に使えるものはないか探していて、 Rust 製の全文検索システム Tantivy と、その Ruby クライアントの Tantiny を発見した。
これがめっちゃ簡単で昨日数時間サンデープログラミングをして導入できた。システム環境に適合するビルド済みのバイナリが GitHub にあれば Rust 環境のセットアップすら必要ない。 Gemfile に gem 'tantiny' と書いて bundle install するだけで使えてしまう。
うまくいかなかったもの
最初、同じ Rust 製で Wasm までセットで提供してくれる tinysearch を試した。 JSON 形式で全ファイルを書き出すだけで使えるやつだ。しかし残念なことに日本語では全く使えなかった。自然言語処理をやろうとしていてあるあるのパターンだ。日本語は MeCab などでトークナイズしてやる必要がある。
デフォルトのトークナイザーでもそこそこに優秀な Tantivy
Tantivy にもトークナイザーをカスタマイズできる仕組みはあるが、標準の Simple Tokenizer でもそこそこ精度が高い。固有名詞にちょっと弱いが、辞書ファイルがないので仕方ないだろう。
個人ブログでも全文検索できる時代
このブログは個人ブログだが、画像のリアルタイムリサイズサーバーを動かしている(おかげで S3 の転送量が安くて済んでいる)し、 TF-IDF で関連の高い記事も表示している。それに加えて全文検索まで入れてしまった。こういうのは大手のブログサービスを利用しないと使えない機能だったが、 OSS と新しいプログラミング言語( Go や Rust )のおかげで個人でもそこそこのスペックのサーバーでこれらを利用することができるようになってきた。 MovableType でサイトを構築していた時代から何も進歩していないようで実はとても進歩している。こういう文化の灯火が消えないようにしていきたい。