cho45 さんの以下の記事を参考に関連記事を表示するようにしてみた。

ほとんど cho45 さんの記事に書いてある SQL を実行しているだけだけど、関連記事の表示用に Lokka 側に Similarity というモデルを追加して、以下のようなスキーマにしてる。

Similarity テーブルの更新は cho45 さんの記事にあるように SQLite で行った計算の結果を反映することで行う。以下のような Rake タスクを定義した。
desc "Detect and update similar entries"
task similar_entries: %i[similar_entries:extract_term similar_entries:vector_normalize similar_entries:export]
namespace :similar_entries do
require 'sqlite3'
desc "Extract term"
task :extract_term do
require 'natto'
nm = Natto::MeCab.new
db = SQLite3::Database.new('db/tfidf.sqlite3')
create_table_sql =<<~SQL
DROP TABLE IF EXISTS tfidf;
CREATE TABLE tfidf (
`id` INTEGER PRIMARY KEY,
`term` TEXT NOT NULL,
`entry_id` INTEGER NOT NULL,
`term_count` INTEGER NOT NULL DEFAULT 0, -- エントリ内でのターム出現回数
`tfidf` FLOAT NOT NULL DEFAULT 0, -- 正規化前の TF-IDF
`tfidf_n` FLOAT NOT NULL DEFAULT 0 -- ベクトル正規化した TF-IDF
);
CREATE UNIQUE INDEX index_tf_term ON tfidf (`term`, `entry_id`);
CREATE INDEX index_tf_entry_id ON tfidf (`entry_id`);
SQL
db.execute_batch(create_table_sql)
entries = Entry.published.all(fields: [:id, :body])
entry_frequencies = {}
entries.each do |entry|
words = []
body_cleansed = entry.body.
gsub(/<.+?>/, '').
gsub(/!?\[.+?\)/, '').
gsub(/(```|<code>).+?(```|<\/code>)/m, '')
begin
nm.parse(body_cleansed) do |n|
next if !n.feature.match(/名詞/)
next if n.feature.match(/(サ変接続|数)/)
next if n.surface.match(/\A([a-z][0-9]|\p{hiragana}|\p{katakana})\Z/i)
next if %w[これ こと とき よう そう やつ とこ ところ 用 もの はず みたい たち いま 後 確か 中 気 方 頃 上 先 点 前 一 内 lt gt ここ なか どこ まま わけ ため 的 それ あと].include?(n.surface)
words << n.surface
end
rescue ArgumentError
next
end
frequency = words.inject(Hash.new(0)) {|sum, word| sum[word] += 1; sum }
entry_frequencies[entry.id] = frequency
end
entry_frequencies.each do |entry_id, frequency|
frequency.each do |word, count|
db.execute("INSERT INTO tfidf (`term`, `entry_id`, `term_count`) VALUES (?, ?, ?)", [word, entry_id, count])
end
end
end
desc "Vector Normalize"
task :vector_normalize do
db = SQLite3::Database.new('db/tfidf.sqlite3')
load_extension_sql =<<~SQL
-- SQRT や LOG を使いたいので
SELECT load_extension('/usr/local/Cellar/sqlite/3.21.0/lib/libsqlitefunctions.dylib');
SQL
db.enable_load_extension(true)
db.execute(load_extension_sql)
update_tfidf_column_sql = <<~SQL
-- エントリ数をカウントしておきます
-- SQLite には変数がないので一時テーブルにいれます
CREATE TEMPORARY TABLE entry_total AS
SELECT CAST(COUNT(DISTINCT entry_id) AS REAL) AS value FROM tfidf;
-- ワード(ターム)が出てくるエントリ数を数えておきます
-- term と entry_id でユニークなテーブルなのでこれでエントリ数になります
CREATE TEMPORARY TABLE term_counts AS
SELECT term, CAST(COUNT(*) AS REAL) AS cnt FROM tfidf GROUP BY term;
CREATE INDEX temp.term_counts_term ON term_counts (term);
-- エントリごとの合計ワード数を数えておきます
CREATE TEMPORARY TABLE entry_term_counts AS
SELECT entry_id, LOG(CAST(SUM(term_count) AS REAL)) AS cnt FROM tfidf GROUP BY entry_id;
CREATE INDEX temp.entry_term_counts_entry_id ON entry_term_counts (entry_id);
-- TF-IDF を計算して埋めます
-- ここまでで作った一時テーブルからひいて計算しています。
UPDATE tfidf SET tfidf = IFNULL(
-- tf (normalized with Harman method)
(
LOG(CAST(term_count AS REAL) + 1) -- term_count in an entry
/
(SELECT cnt FROM entry_term_counts WHERE entry_term_counts.entry_id = tfidf.entry_id) -- total term count in an entry
)
*
-- idf (normalized with Sparck Jones method)
(1 + LOG(
(SELECT value FROM entry_total) -- total
/
(SELECT cnt FROM term_counts WHERE term_counts.term = tfidf.term) -- term entry count
))
, 0.0);
SQL
db.execute_batch(update_tfidf_column_sql)
vector_normalize_sql = <<~SQL
-- エントリごとのTF-IDFのベクトルの大きさを求めておきます
CREATE TEMPORARY TABLE tfidf_size AS
SELECT entry_id, SQRT(SUM(tfidf * tfidf)) AS size FROM tfidf
GROUP BY entry_id;
CREATE INDEX temp.tfidf_size_entry_id ON tfidf_size (entry_id);
-- 計算済みの TF-IDF をベクトルの大きさで割って正規化します
UPDATE tfidf SET tfidf_n = IFNULL(tfidf / (SELECT size FROM tfidf_size WHERE entry_id = tfidf.entry_id), 0.0);
SQL
db.execute_batch(vector_normalize_sql)
end
desc "Export calculation result to MySQL"
task :export do
db = SQLite3::Database.new('db/tfidf.sqlite3')
create_similar_candidate_sql = <<~SQL
DROP TABLE IF EXISTS similar_candidate;
DROP INDEX IF EXISTS index_sc_parent_id;
DROP INDEX IF EXISTS index_sc_entry_id;
DROP INDEX IF EXISTS index_sc_cnt;
CREATE TABLE similar_candidate (
`id` INTEGER PRIMARY KEY,
`parent_id` INTEGER NOT NULL,
`entry_id` INTEGER NOT NULL,
`cnt` INTEGER NOT NULL DEFAULT 0
);
CREATE INDEX index_sc_parent_id ON similar_candidate (parent_id);
CREATE INDEX index_sc_entry_id ON similar_candidate (entry_id);
CREATE INDEX index_sc_cnt ON similar_candidate (cnt);
SQL
db.execute_batch(create_similar_candidate_sql)
extract_similar_entries_sql = <<~SQL
-- 類似していそうなエントリを共通語ベースでまず100エントリほど出します
INSERT INTO similar_candidate (`parent_id`, `entry_id`, `cnt`)
SELECT ? as parent_id, entry_id, COUNT(*) as cnt FROM tfidf
WHERE
entry_id <> ? AND
term IN (
SELECT term FROM tfidf WHERE entry_id = ?
ORDER BY tfidf DESC
LIMIT 50
)
GROUP BY entry_id
HAVING cnt > 3
ORDER BY cnt DESC
LIMIT 100;
SQL
search_similar_entries_sql = <<~SQL
-- 該当する100件に対してスコアを計算してソートします
SELECT
? AS entry_id,
entry_id AS similar_entry_id,
SUM(a.tfidf_n * b.tfidf_n) AS score
FROM (
(SELECT term, tfidf_n FROM tfidf WHERE entry_id = ? ORDER BY tfidf DESC LIMIT 50) as a
INNER JOIN
(SELECT entry_id, term, tfidf_n FROM tfidf WHERE entry_id IN (SELECT entry_id FROM similar_candidate WHERE parent_id = ?)) as b
ON
a.term = b.term
)
WHERE similar_entry_id <> ?
GROUP BY entry_id
ORDER BY score DESC
LIMIT 10;
SQL
results = {}
Entry.published.all(fields: [:id]).each do |entry|
db.execute(extract_similar_entries_sql, [entry.id, entry.id, entry.id])
db.results_as_hash = true
similarities = db.execute(search_similar_entries_sql, [entry.id, entry.id, entry.id, entry.id])
results[entry.id] = similarities
end
Similarity.destroy
results.each do |entry_id, similarities|
if similarities.present?
similarities.each do |s|
conditions = { entry_id: s["entry_id"], similar_entry_id: s["similar_entry_id"] }
similarity = Similarity.new(conditions)
similarity.score = s["score"]
similarity.save
end
end
end
end
endやってることとしては、全エントリーを拾ってきて本文を MeCab で品詞分解して名詞だけを取り出し記事ごとの term 一覧を作り、そこから TF-IDF を求めてベクトル正規化し、最後に関連していそうなエントリを探し出して similarities テーブル(こちらは SQLite のテーブルではない)を更新している。詳しいアルゴリズムはバカなのでわからないが、 cho45 さんが書いているやり方を Lokka のスキーマに素直に適用した感じ。
結構この処理は遅いので parallel.gem を使って高速化できないか試してみたが、スレッドによる並行処理ではあまり速くできなかった。 4 コアある CPU のうち一つが 100% で処理を実行してもまだ 3 コアは余っている。プロセスを増やして並列処理するのがよさそうだが、分散をプロセスレベルで行おうとすると MySQL server has gone というエラーが出る。 DataMapper が MySQL とのコネクションをロストするようである。 ActiveRecord であれば reconnect するだとか回避方法があるようなのだけど DataMapper は情報が少なく、対応方法が見つけられなかったので一旦並列処理はあきらめた。
何回か動かしてみて大体正しく関連記事を表示できてそうなのでさくらの VPS で稼働させたいところなのだけど、関連記事の更新はいまのところ手動でやっている。本番 DB の entries テーブルを dump してきて Mac に取り込み、 similarities テーブルを更新して今度はローカルで similarities テーブルを dump して本番にインポートするという手順をとっている。
これにはいろいろ理由があって、一つには利用している mecab-ipadic-neologd (新語にも対応している MeCab の辞書)が空きメモリ 1.5GB 以上でないとインストールできずさくらの VPS にインストールできなかったから。もう一つには cho45 さんのブログにもあるけど SQLite で LOG や SQRT を使うためには libsqlitefunction.so の読み込みが必要で、 load_extension() できるようにしないといけないが、そのためには sqlite3 をソースからビルドする必要があり若干面倒だった( Mac では Homebrew で sqlite を入れた)。
関連記事の更新は自分が記事を書いたときにしか発生しないのでいまの手動運用でもまぁ問題ないが、このブログは Docker でも動くようにしてあるので Docker イメージを作ればさくら VPS でも問題なく動かせそうな気はする。正月休みにでもチャレンジしたい。
感想
関連記事表示、結構面白くてちゃんと関連性の高いエントリーが表示される。例えば人吉に SL に乗り行った記事の関連記事にはちゃんと山口に SL に乗りに行ったときの記事 が表示される。いまのところ Google Adsense の関連コンテンツよりも精度が高いようである。
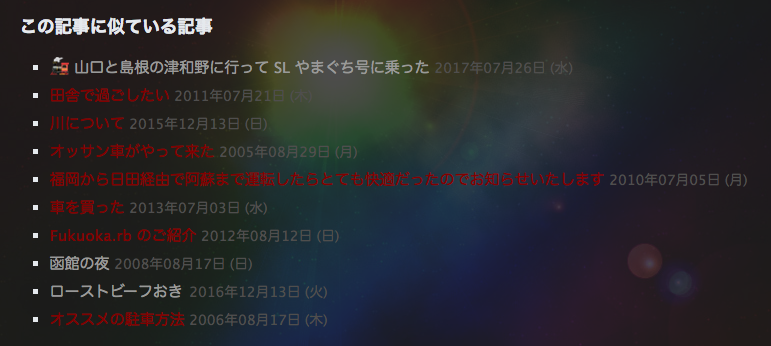
無限に自分の黒歴史を掘り返すことができるのでおすすめです。