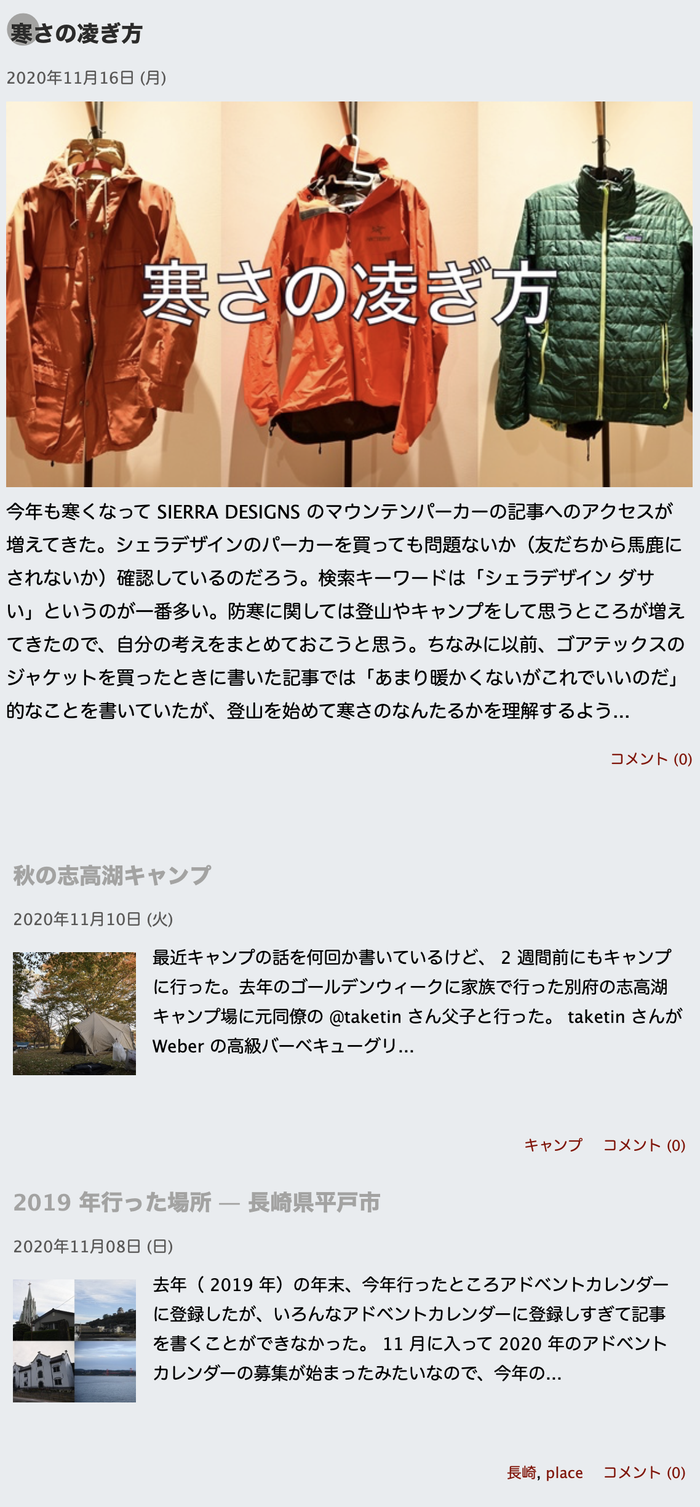
ダークモードとライトモードの切り替えをグローバルナビゲーション(上の方の半透明の白い領域)から簡単に行えるようにした(これまではこのサイトについてのページで切り替える必要があった)。デフォルトは OS の設定準拠で、 OS がダークモードであればダークモードに、ライトモードであればライトモードで表示される。手動でテーマを切り替えると Cookie に設定値を保存する。機能と見た目は MDN Web Docs を参考にした。
CSS がぐちゃぐちゃなのでかなり難儀した( 3 年前にも同じことを書いている)。ダークモードとライトモードの切り替えなんて自分しかしていないと思うがかなり満足度の高い休日プログラミングだった。