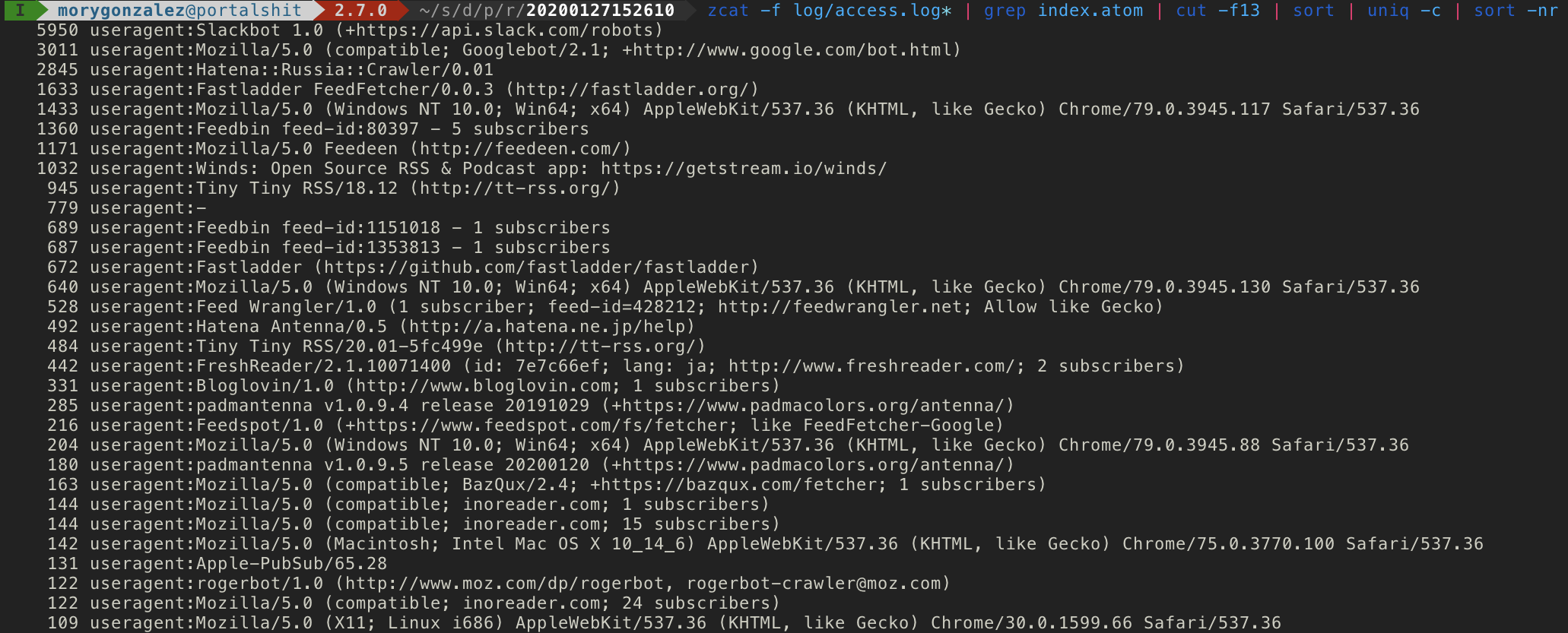
スマートフォンで検索していてある大手ブログサービスでホストされているブログの記事に辿り着いた。記事を読んでいくと、ページ構造が「パーマリンクとは?」という感じになっていて驚いた。まるで蟻地獄で、下にスクロールしても終わりがなく、一度入り込んだら逃げられない感じだった。一つの URL に一つのコンテンツというインターネットのお約束を無視していて、 URL は個別記事のものだけど、下までスクロールすると次の記事の本文が読み込まれる。さらにスクロールするとそのまた次の記事が読み込まれる。 AutoPagerize がページャーのないところでも有効化されている感じで、読者の好みで無効化できない状態になっていた。
記事と記事の間には芸能ニュース記事へのリンクが差し込まれたり、そのブログサービス内で人気の記事ランキングが挟まれたりする。 A さんのブログを読んでいたはずなのに気がつくとゴシップニュースか他の人の炎上記事を読むことになっている。おまけにそこに広告も挟まれてくる。ページ内で URL が指し示すオリジナル記事の分量が 10% に満たないこともあるんじゃないだろうか。書き手にとっても読み手にとっても体験が良くない。大手のブログサービスはどこも同じような感じで、他のニュース記事や人気記事への誘導が激しい。
Twitter を追い出されたあとの Evan Williams が Medium を始めたときは意味がわからなかった。今時ブログサービスなんて始めてどうするんだろうと思った。はてなブログに関しても、なぜいま新しいブログサービスが必要なのかわからなかった。しかしいまならその理由がわかる気がする。
インターネット上でのコミュニケーションの場がブロゴスフィア(死語)から SNS へ移り、ブログの読者は SNS を流し読みしていてタイムラインに流れてきたコンテンツを消化するだけ。著者はコンテンツを提供するだけの存在となってしまい、両者の間でインタラクティブなやりとりが生まれなくなった。そんな状況でもう一度著者と読み手を中心に据えようとして始まったのが Medium だったのではないだろうか。

Medium もはてなブログも広告は表示されないか表示されても少しだし、 Medium の人気記事への誘導は控えめで、はてなブログは同一ブログ内の記事しかお勧めしてこない。
はてなブログを開始されて間もないときに jkondo が書いている記事の最後にこんなフレーズが出てくる。
「個」としての活動が、人生に新しい展開を持ち込み、より豊かな人生につながります。
SNS 、ブログ、あらゆるところで巨大なサービス(=プラットフォーム)が幅を効かせて個人を飲み込もうとしているいま、どこでブログを書くと一番記事の価値を毀損しないかまで考えてブログを書く場所を選んだ方がよいと思う。はてなブログや Medium 、 note も流行ってるっぽいが、自分としてはやっぱり自分のブログを持つのが最高だと思ってる。

独立自営のブログをやる人の選択肢を増やすために、今後も Lokka のメンテナンスはやっていきたい。やりたい・やると宣言して出来てないことだらけで申し訳ないけど、少しずつこのブログの機能を master ブランチに移植していって 2020 年でも常用できるブログにしていきたい。ちなみに以下は Markdown をオン・ザ・フライでプレビューする機能の Pull Request 。
あと Slack に Workspace を作った。何年か前に調べたときは lokka.slack.com が空いてたんだけど誰かに取られてたので lokkahq.slack.com となった。良かったら入ってください。ちなみにまだ僕しかいません。
追記 2020-04-13
cho45 さんの昔のブログ記事を読んでたらわかる(わかる)という記事があったのでリンクしておきます。


ノウハウ蓄積みたいなコンテンツってASP型で預けるのは不安がありすぎるので、自力で配信しようねみたいなウェブ縄文時代みたいな話になるんですが……
ウェブ縄文時代 ってのは言い得て妙だと思いました。残念だけど一周回って個人ウェブサイトは縄文時代を迎えつつあるんだと思う。