職業プログラマーになって 8 年の間に随分とジョブホッピングを繰り返してきたが、どこの会社でも評価が良くない。上司(非技術者であったことがほとんど)からは全く評価されない。なので在職時に昇給したということはほぼない。ペパボ時代にエンジニア評価制度が導入されてシニアエンジニア1になったときにががっと給料が上がったことはあったけど、あれは直属の上司ではなく技術責任者から評価されるという仕組みだったのでイレギュラーケースといえると思う。その後は転職時に増えた以外では全然給料が増えたことはない。据え置きが続いたりむしろ下がったことすらある。
しかし一度退職すると、同じチームの同僚や隣のチームの偉い人とかから良く思われていたことが判明することが多い。戻ってきてほしいとか、いなくなって困ってるとか。当然社交辞令の部分もあると思うが、全く役に立たないクソ野郎だったらそんなことを社交辞令で言われることもないはずなんで、ある程度は評価されていたといえるんだと思う。
なぜ在職中に上司から評価されないのか考えると、当時の上司がやってほしいと思ってることをやらないからだと思う。自分はチーム全体で効率が良くなるようにツールをあれこれしたり bot でガチャガチャやったりとか( Developer Productivity の向上)が好きなんで、自分の動きは会社がやりたいこと、上司がやらせたいこと(売り上げが増える何か、アプリのダウンロード数が増える何か)に直接寄与していないよう見える。
前職や現職で新しくプロジェクトが動き始めるときに何は無くともユニットテストを実行できる仕組みと Docker や CI 環境の構築をガガっとやってて、誰もがテスト書いて Pull Request 出して CI パスしてからレビュー依頼してデプロイも確認環境には自動でじゃんじゃんデプロイされて( Continuous Delivery )、誰も(新人やプログラマーでない人含む)が簡単に本番にもデプロイできる仕組みを作ったという自負がある。こういうのは直接売り上げは増やさないけど開発サイクルを早めたりチームの生産性を高めたりしていると思うが、1秒でも早く依頼したソフトウェアを納品してほしい人からはなんか勝手なことをやってるように見えるし、それが当たり前になると特にありがたみを感じられない種類のものなので評価の対象となりにくい。問題が起こって仕組みが使えなくなったときに初めてありがたみがわかる。なので在職中には評価されない。少なくとも上司からは。
加えて、自分には理想主義的なところがあって、訳の分からない指示が来たときに「そもそもそれいまやることですか」とか「会社がやるべきなのは違うことじゃないですか」と言ってしまう。そもそも論を言うので、ミーティングに参加していても荒れたり脱線してしまったりして「こいつ今これ言うのかよ…」みたいな冷たい視線を浴びることがよくある。場をかき乱す発言をするので「こいつはわかっていない」という烙印を押されてしまう。
評価が良くないと、長く同じ会社に留まり続けるメリットが得られず転職を繰り返してしまう。正直なところ転職は面接を受けに行ったり、給与交渉をしたり、退職を打診したり、仲の良い同僚と別れたり、有給がリセットされたり、人間関係を作り直したり、健康診断の履歴が失われたり、ローンを組むとき不利になったりでしんどいことが多い。できる限り同じ職場で働き続けることがハッピーだろうなぁとは思うんだけど、会社から評価されないのは不満が溜まるし、自分のような人間(間接的にだが結構会社の役に立ってる)が評価されないのはその組織にとっても良くないと思えて転職するという選択をしてしまう。良くない。会社が自分の評価を良くせざるを得ない状況に持ち込めるくらいに腕力(プログラミング能力)や胆力(度胸)をつけなければならないんだろうなぁとは思ってる。
※ なおこの記事は退職エントリーではありません。
-
今にして思うと当時の自分は全くシニアではなくジュニアだった https://portalshit.net/2018/10/02/we-should-hire-junior-engineers ↩
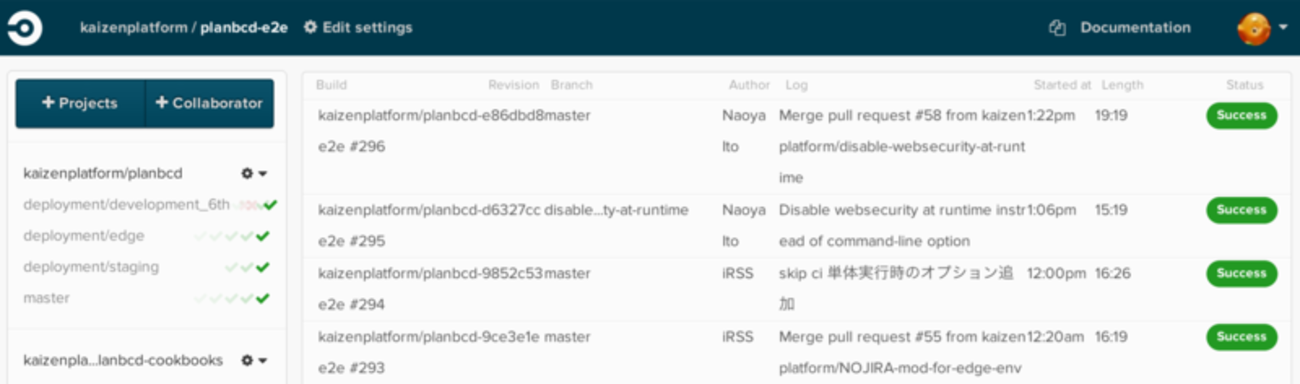
 転職して一年が経った。まだまだ課題はあるが、職業エンジニアになってからでは飛躍的に成長できた一年だったと思う。大きかったのはインフラ関連の技術の習得で、 Docker での開発環境構築、 CircleCI を活用したビルドとデプロイの仕組みの構築、 Terraform を使ったインフラのコード化、オートスケールの仕組みの構築など、これまで担ってこなかったタスクを担当することができ非常に得るものが大きかった。これまで在籍してきた職場ではこれらのタスクに関して自分よりも圧倒的に優れた人たちがいたので自分が手を出せるような隙がなかった。小さなスタートアップは慢性的に人手が足りていないので『隙』は無数にあり、これまでのキャリアで担当できなかったタスクに手を出しやすい。自分にはまだまだ技術的な伸び代があることがわかり、 35 歳定年説なんてちゃんちゃらおかしいわ、と思えるほどにこれからも全然エンジニアとしてやっていけそうな気がしている。とはいえあんまり調子こいてると足をすくわれると思うので、自信を持ちつつも尊大にならず良い感じに余生を過ごしたい。
転職して一年が経った。まだまだ課題はあるが、職業エンジニアになってからでは飛躍的に成長できた一年だったと思う。大きかったのはインフラ関連の技術の習得で、 Docker での開発環境構築、 CircleCI を活用したビルドとデプロイの仕組みの構築、 Terraform を使ったインフラのコード化、オートスケールの仕組みの構築など、これまで担ってこなかったタスクを担当することができ非常に得るものが大きかった。これまで在籍してきた職場ではこれらのタスクに関して自分よりも圧倒的に優れた人たちがいたので自分が手を出せるような隙がなかった。小さなスタートアップは慢性的に人手が足りていないので『隙』は無数にあり、これまでのキャリアで担当できなかったタスクに手を出しやすい。自分にはまだまだ技術的な伸び代があることがわかり、 35 歳定年説なんてちゃんちゃらおかしいわ、と思えるほどにこれからも全然エンジニアとしてやっていけそうな気がしている。とはいえあんまり調子こいてると足をすくわれると思うので、自信を持ちつつも尊大にならず良い感じに余生を過ごしたい。