生活
ランニングレース
熊本城マラソン
直前の食あたりと靴の取り間違いでコンディション最悪だった。加えて転倒もあり、マラニック状態で 5 時間オーバーでゴール。リタイアしなかったのは偉い。来年は雪辱を果たしたい。

ASO VOLCANO TRAIL
初のウルトラトレイル( 112km )。3 月、 4 月と自分にしてはしっかりトレーニングしてから臨んだ。25 時間以上かかって記録はいまひとつたが、完走できたことがうれしかった。
トレーニングで三瀬峠脊振山ピストン練を 3 回やって、糸島四座縦走が楽に感じられるくらい強くなった( 4 時間半でゴールできた)。ターゲットレースがあると、それに合わせて頑張るので走力がぐっと上がる。 5'10"/km くらいのペースで走るのがそんなにしんどくなくなった。

福岡マラソン
直前期にあまり走れていなかったので不安だったが、マラソン自己ベストを更新できた。もう少し練習して体重も落とせていたらもっと速く走れたかもしれない。

総括
レースはマラソン 2 本とトレラン 1 本だった。カントリーレースも出たかったがうっかりしていて締め切られていてエントリーできなかった。
ボルケーノに出るためにだいぶ時間とお金を使ったので他のレースには出なくても良いかなぁと思っていたが、やはりたまにはレースに出ないと張り合いがない。来年はもうちょいレースに出たい。
登山・トレラン
脊振山系全山縦走トレラン
初めての夜通しのトレラン。 ASO VOLCANO TRAIL の予行演習になった。同僚にサポートしてもらってめっちゃうれしかった。

祖母・傾ファストパッキング
いわゆる祖母傾完全縦走。九合目小屋に泊まった。 20L の Rush 20 では宿泊装備が入りきらなかった、 Rush 30 も買うか…

高尾山ハイキング
出張ついでに訪問、日本で一番登山者が多い山を訪れることができた。トレラン装備の人が多かった。ハイキングの人もトレラン装備で登ってた。結構年齢が上の人でもトレラン風の装備だった。来年あたり九州でもそういうスタイルが一般的になるかも。
下山後に食べ飲みした蕎麦とクラフトビールがうまかった。都会の山ならでは。


国見岳山頂祠再建ボランティア
熊本県最高峰の国見岳の山頂祠が倒壊したままなのは、熊本県民にとっては残念だった。再建をすると聞いて、少しでも役に立ちたいと歩荷のボランティアに行った。あまり役には立てなかったが、祠の再建に立ち会えたことは良かった。

八ヶ岳(硫黄岳)登山
出張ついでに訪問、九州の山ばかり登っていてはダメだと若い同僚にけしかけられて登りに行った。八ヶ岳、ガスガスで何も見えなかったが、久しぶりの森林限界突破と、有人の営業小屋のもてなしで心がほっとした。防風のなか、雨風を凌いでゆっくりできる場所を用意してもらえてるだけでありがたい。

インターネットトレラン
nagayama さん、 nmy さんとのインターネットトレランも思い出深い。インターネットとトレランという二つの趣味の交錯だし、なんなら仕事と趣味の交錯でもあり、とてと楽しい時間だった。

坊がつる野営( Happy Hikers Hokkein Gathering )
同僚と行ったが野営したのは一人(途中から別行動)。一昨年の方が寒かったが、 Hammock Bivvy Tyvek を使わなかったので寒くて眠れなかった。野営は定期的にやってないと勘が鈍って失敗する。

韓国岳
寒い日に登り、雪景色の山を堪能した。えびの高原は雰囲気抜群で、またキリエビに出たいなと思った。

南阿蘇カルデラトレイルボランティア
二度ほど出場したことがある南阿蘇カルデラトレイルにボランティアとして参加した。ボランティアしんどい。 4 時半集合だったので 1 時半に起きて 2 時過ぎに福岡の家を出て向かった。自分が出た年は雪が降っていてソフトフラスクが凍り付いたが、今年はあたたかくて走りやすそうだった。自分もまたレースに出たくなった。

総括
脊振山系全山縦走と祖母傾完全縦走が思い出に残っている。どうしても限界までチャレンジするような登山の方が印象に残りやすい。年に 1 、 2 回、こういう登山をするといいのかも。
一方で、高尾や八ヶ岳、韓国岳へののんびりハイクも楽しかった。きつい登山とゆるハイクをバランス良くやりたい。ハードなトレランばかりだと疲れる。
今年は九州脊梁に泊まり登山に行けなかったのが残念。年に一回は脊梁で野営らしい野営をしたい。
買い物
Novablast 5
レースシューズに Magic Speed 2 を持っていたが、デイリートレーナーでは初のアシックス。めっちゃ走りやすくてランニングが楽しくなった。ベアフットシューズで足は鍛えられるがどうしても距離が踏めない。アルトラは良いが値段が高すぎる。アシックスがコスパよい。

iPhone 17 Pro
iPhone 14 Pro からの買い換え。目玉が飛び出るほど高かったが iPhone 14 Pro の下取り価格が高くて助かった。カメラのデザインはどうかと思うが画質がメチャ良くなっててうれしい。 USB-C ケーブルになったのも地味に便利。

Garmin Epix Pro
検証機で Garmin Fenix 7 を使って Garmin に宗旨替えすることにした。 Garmin はヘルスケアや運動関連で踏み込んだアドバイスをしてくれる。 Apple Pay や Mac や iPhone のロック解除、 Siri は便利だったがランニングが趣味なら Garmin が一番いいと思う。

OTTO Cast Mini
Car Play がワイヤレス化されて最高便利。Amazonアソシエイトリンクを貼ったら結構買ってもらえててビックリ。みんな同じような悩みを抱えているっぽい。
HOUDINI Moon Walk Vest
これはガジェット系ではなく服。ほぼ毎日着ている。秋はTシャツの上に羽織り、冬もフリースの上に羽織ったりしてる。暑がりなのでダウンジャケットなどは暑すぎる。こういうのがちょうど良い。

水出し緑茶ティーバッグ
社長からもらって気に入って自分で買って飲むようになった。水出しでよく出ておいしい。一パックあたり 50 円くらい。毎日ペットボトルのお茶買うのは環境に良くないしお金ももったいない。

総括
年をとったせいか、同じものをスペアで買ったり、買い置きを増やすことが多くなった。その結果見つからなくなったり、食べ物なら腐らせてしまったりする。もっと賢くお金使えるようになりたい。
音楽・本・映画
国宝
Audible で聞いたがめっちゃよかった。映画見に行きたいが暇がなくて行けてない。

Yogee New Waves
ライブに行った。 Good Bye をすり切れるくらい聞いた。
Oasis
ライブのチケットは何度も申し込んだけど当たらなかった。 Live Forever と Supersonic と Acquiesce を何度も聞いた。 Live Forever は 95 年の Glastonbury でのライブバージョンがよい。
Wilderado
スターバックスの店内 BGM を聞いて知ったインディフォークロックバンド。 Surefire という曲がめっちゃいい。いつかアメリカでライブに行ってみたい。
総括
映画は1本も見てない。ドラマすら見てない。 YouTube ばかり見てしまった。来年は1本くらい映画見たい。
ブログ
写真でふりかえるシリーズを 12 ヶ月分書いた
書くネタがないが写真の整理がてら毎月ふりかえるのはよかった。今後も続けたい。

Ruby 3 で動くようにした
Ruby 2.7 で動かしていたのでとりあえず最低限の対応をして Ruby 3.1 にした。 Ruby 3.1 も EOL を迎えているのでなんとかしたい。



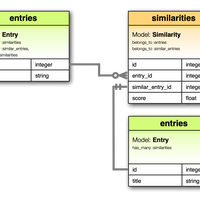
フォトギャラリー
私家版 Flickr のようなやつを作った。撮った写真をどこかに上げたいたいという欲求があったが、 Instagram はなんかちょっと違う。 Flickr のような場所が良いが、いまの Flickr は値段が高すぎるのでフォトギャラリー機能を実装してしまった。ちょうど良いアウトプットの場が作れてうれしい。

AI を使って機能の追加
要約生成、自動タグ付け機能を作った。 Dify を使ってポータルシット問いかけ君( AI チャットボット)も使った。開発のサポートだけじゃなく、機能の一部として AI を使う時代になってきてる。
総括
職業エンジニアじゃなくなってブログの維持管理がさすがに厳しくなってきた。いつまでできるかわからないがボケ防止と思って頑張る。
仕事
プロダクトマネジメント
プロダクトマネージャーの役割に葛藤する一年だった。結局、経営やビジネスサイドに言われたことを実行するだけで、プロダクトマネージャーはプロジェクトマネジメントしかやれてなくてつまらない、という不満を部下から聞かされることが多かった。やりがい云々の前に、確かにビジネスとプロダクトが分断されていてなかなか大きな成果を出せなかった。この構造をなんとかしなければならないが、しかしこのような分断が起きるのは自分を含むプロダクトマネージャーが身銭を切りきれていないからではないかと思い至った。コンフォートゾーンを出てリスクを取りにいかないと信頼されないし、大きな権限は渡してもらえない。もっとプロダクトマネージャーが事業を引っ張っていくような体制をつくっていきたい。
とはいえ、必ずしもプロダクトマネージャー自身が革新的なアイディアを思いつく必要はなくて、プロダクトディスカバリーのプロセスをめっちゃ丁寧にやることが大事だと思う。なぜこのプロダクトを自分たちが作る必要があるのか、このプロダクトで世の中にどんな変化を引き起こすのかをつまびらかにする。この部分だけで記事が書けるので別に書こうと思う。
開発部長業
エンジニアに対してもプロダクトマネージャーと同じで、もっとリスクをとってほしいと思うことがしばしばあった。9月にバズってた以下の記事が良かった。
心理的安全性についても結構議論した。職場ではこれまでも心理的安全性を高めることが大事だと言われてきたが、なぜ心理的安全性を高める必要があるのかについての議論が不足していたように思う。働きやすさとかそういうのは二の次で、個々人にフィードバックが適切に行われ、フィードバックによって学びを得て生産性を高めていくことが開発組織における心理的安全性を高めなければならない根拠になると思う。心理的安全性がなければフィードバックをする方は怖くてフィードバックできないし、フィードバックを受ける方も個人攻撃ではないという確信がなければそのフィードバックを素直に受け止めることができない。
これらが機能するために、ダニエル・キムの成功循環モデルはめっちゃ重要だと思う。関係性の質、思考の質、行動の質、結果の質にはループ構造になっているというもの。めっちゃスタープレイヤーが揃っているチームじゃなくても、関係性の質が良ければ結果を出すということは身をもって知った。自分が何となくチームビルディングできていたのでなんとかなるだろうと思っていたけど、これは仕組み化しないとダメだとわかった。チームビルディングをチーム任せにせず、少々御節介でも組織として積極的に関与していくことが大事だと思う。
総括
自分は起業できるほど人間力高くないが、それでも世の中に影響を及ぼすことをやって人生終えられる仕事がいまのような仕事(中間管理職兼プロダクトマネージャー)なのかなと思ってる。来年はどうすればもっと自分の強みが生きるのか考えて行動していきたい。なんのかのと書いているが、とにかく結果を残したい。