この記事は CircleCI Advent Calendar 2018 19 日目の記事ですが間に合わず一日遅れて書いております。すんません 🙇🏻
CircleCI を使った Rails アプリのデプロイフローみたいな話を書こうかなと思ったのですが、すでに他の方が書いてる内容とかぶりそうだし、自分自身ブログに過去何回も書いた話なんで今回はエモ方面の話を書くことにします。技術的な情報はないのでそっち方面を期待している方はすんません。
いまの職場で働き始めて 1 年半なんですが、当初は CI はなく、テストコードもありませんでした。いまはそこで当たり前のように CI が回り、テストのカバレッジもまぁまぁ高く、デプロイは CircleCI 経由でじゃんじゃん行われるような状況となっております。新しく会社に入った人も GitHub の Organization に入ってもらえたらその瞬間から deploy 実行できます。具体的な話は昔書いてますのでよかったらご覧下さい。


8 年くらい前の自分はどうやったら CI だとか自動デプロイだとかできるようになるのか皆目見当が付きませんでした。いま 8 年前の自分と同じような状況にいる人(回りにテストを書く習慣を持つ人がいない人、 CI 動かすためにどうすればよいかわからない人)に何か言いたいと思い筆をとりました。
まずは何はなくとも頑張って一つテストケースを書いてみましょう。最初からカバレッジ 100% とか目指さなくてもよいです。どれか一つ、テストが書きやすそうなコードを見つけてテストを書き、ローカルで実行してテストがパスするのを確認しましょう。テストファーストとかも最初から目指さなくてよいです。
手元でテストが通ることを確認したら、 CI 環境でもテストを実行できるようにしましょう。
昔は Jenkins しか選択肢がなく、 Jenkins が動く環境をセットアップする(サーバーを調達する、 VPS を借りてもらう、などなど)に社内調整が必要でしたが、 CircleCI ならプライベートリポジトリでも 1 プロセスなら無料で使えますので社内調整が非常に楽です(外部にコード出してはダメな職場だと厳しいですね…)。
最初にプロジェクトを追加して言語を選ぶと設定ファイルが自動生成されるので、それをコピペして .circleci/config.yml として保存し、リポジトリにコミットするだけでとりあえずビルドが実行されるようになります。
昔は難しかった CI 環境構築のうち、お金の問題、設定の難しさの問題を CircleCI は解決してくれます。あとはあなたが頑張るだけです。
CircleCI ならビルド終了ごとに結果を Slack などチャットシステムに通知させることができます。まずはテストケースが一つでもよいのでリポジトリへの push をトリガーにビルドが実行されたら結果を Slack に通知してみましょう。


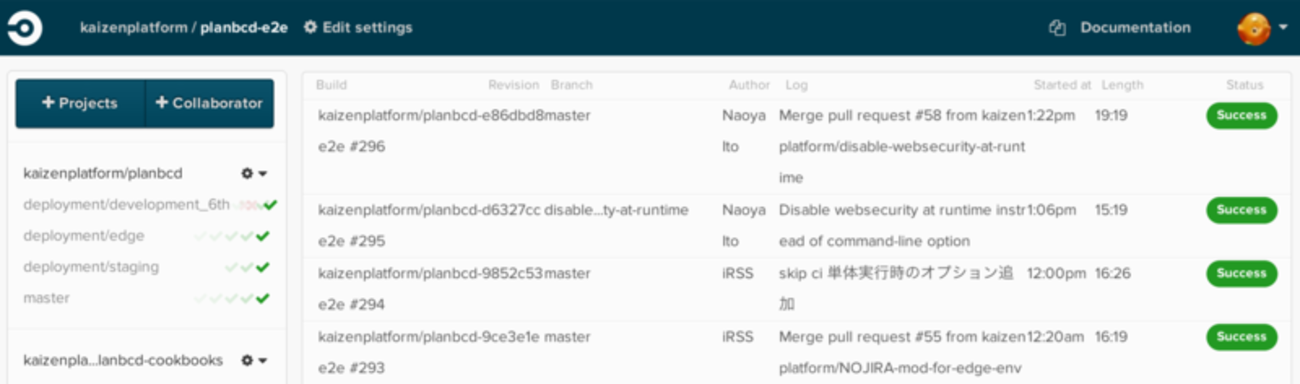
リポジトリに GitHub を使っているなら Pull Request にビルド結果が表示されるようになるはずです。

これらで「なんかようわからんけどやっとる感」を出していきましょう。
そして過去のコードのことは一旦無視して、あなたが新しく追加する部分に関してはテストコードをセットで書くようにしていきましょう。あなたがコードレビューを依頼するときには必ずテストがグリーンな状態で依頼するようにするのです。
そうこうしているうちに他の人が出した Pull Request でテストが失敗するケースが発生します。 Slack の #circleci チャンネルに赤色の Failure 通知が届き社内が騒然とするかもしれません。しかしこれはチャンスです。
「よかった、これでバグが未然に防げましたね」
あなたのこの一言でテストや CI がもたらす開発効率の向上がチームの皆さんに伝わるはずです。こうなったらもう一押しです。あなたがテストと CI の伝道師になりましょう。テストを書くことが当たり前になってきたら、 CircleCI からの deploy や定型処理を CircleCI でやらせるような使い方にチャレンジしていきましょう。どんどん周囲を巻き込んで、 CI 文化を定着させていって下さい。
何はともあれ、最初は一つのテストコードを書くことから始まります。変更に強いコードを書いてじゃんじゃん deploy し、じゃんじゃん Money making していきましょう🤑