OGP の og:image を動的に生成する機能をブログに実装していた( 1 年半も前)。
記事本文中に画像がある記事であれば og:image は本文中に含まれる最初の画像を og:image として設定するようにしている。画像がない文章だけの記事の場合はこれまでサイトのロゴを og:image として表示していた。それだと金太郎飴っぽくなってしまうので、はてなブログとか Qiita とかがやってるみたいに、タイトルとサイトロゴを使って動的に og:image を生成して表示することにした。
- mini_magick をインストール
- 日本語表示用に NotoSansJP-ExtraBold.ttf をダウンロード
- タイトルを載せるための背景画像を作成(画像ソフトで作成)
- 動的に画像を生成するコードを記述
こだわりポイントとしては、日本語のタイトルの折り返し位置をいい感じにするために形態素解析して、ちょうどいい折り返し位置を決定するような処理を実装した。この辺のコードは結構頑張ってる。
def nm
@nm ||= Natto::MeCab.new(
userdic: File.expand_path('lib/tokenizer/userdic.dic'),
node_format: "%M\t%H\n",
unk_format: "%M\t%H\n"
)
end
def prepare_text(text:)
splitted_text = nm.enum_parse(text).map(&:feature)
row_length = 0
result = []
do_loop = true
while do_loop do
splitted_text.each.with_index(1) do |item, i|
result[row_length] ||= ''
if (result[row_length].length + item.length) > INDENTION_COUNT
row_length += 1
result[row_length] = ''
end
result[row_length] += item
do_loop = false if splitted_text.length == i
end
do_loop = false if ROW_LIMIT - 1 > row_length
end
result.each {|item| item.gsub!(/EOS\n\z/, '') }
if result[-1].length == 1
result[-2] += result[-1]
result.pop
end
result.map(&:strip).join("\n").gsub(/"/, '\"').chomp
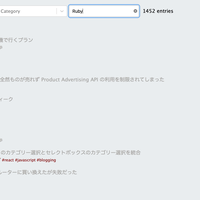
end結果はこんな感じになる。

{kind=link}