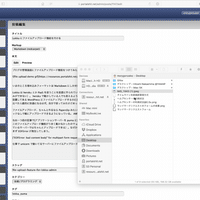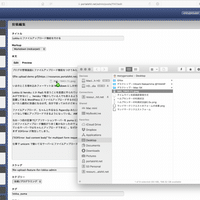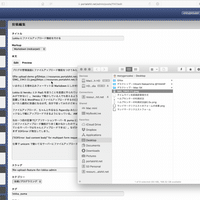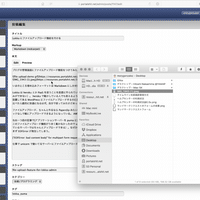
Lokka のプレビューはサーバーサイドに保存時と同じパラメーターを POST して、 DB にレコードを保存せずレンダリングだけ行うが、 GitHub や Kibela のようなタブ切り替えでインスタントに Markdown のプレビューができると便利だろうと思って、 Markdown で編集中に Edit と Preview をタブっぽい UI で切り替えられるようにしてみた。
Markdown のレンダリング自体はサーバーサイドで行っているので、プレビューしたときと実際に保存したときで Markdown の解釈が異なるということもない。
ただリモートで生成した HTML 文字列を DOM に挿入するときに単純に document.innerHTML = body; のようなやり方をしてしまうと JavaScript が動かず困ったので、 iframe を作って document.open(); document.write(body); document.close(); するやり方をとった。そうなると今度は iframe の高さを body のレンダリング終了後に調整する必要があって色々面倒だった。たまに高さがずれたりはするが、基本的にはめっちゃ便利。
Lokka の利用者少ないと思いますが、 Lokka 本体にも入れようと思います。 Ruby の最新版への追従へも最近は行えてないのでこれもやります。