普段は Vim などのテキストエディターで文章を書いていて、ブログの投稿画面にはできあがった内容をコピペするだけだったので、投稿画面の使いやすさやは気にしたことがなかった。画像のドラッグ・アンド・ドロップ・アップロードや、オン・ザ・フライでプレビューをできるようにしたが、テキスト自体の書きやすさを改善しようとはしてこなかった。
大筋はテキストエディターで書いたとしても、最後に推敲したり、推敲していて気が付いたおかしなところの修正は投稿画面で行うことが多い。やっぱり投稿画面の書きやすさは重要だ。特に長大な内容を編集しているときにテキストエリアが狭いととても使いづらい。ある程度大きさがあり、画面内に大量の文字が表示されるテキストエリアが好みだ。
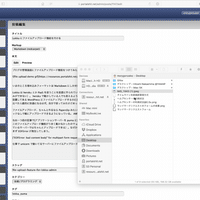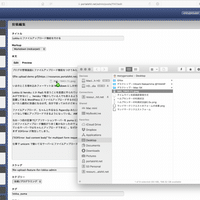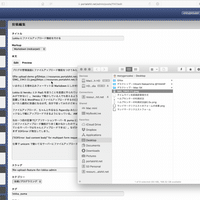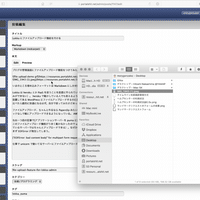
Lokka が開発されていた 10 年以上前は解像度の小さいディスプレイが主流で、 Lokka の管理画面は小さいサイズのウィンドウで閲覧することを想定したテキストエリアのサイズになっている。今日の高解像度ディスプレイで見ると不便なので画面一杯にテキストエリアが広がるようにした。

iPad からも投稿しやすいように投稿画面のレイアウトも修正した。本文のテキストエリアが広がったためスクロールしないと「スラッグ」以降の入力欄にアクセスできなくなったので、ある程度横幅のあるウィンドウのときにはこれらを右側に配置するようにした。
加えて、フォームを書きかけで保存したかどうかがはっきりせず、未保存の内容があるのに保存せずページから離脱してしまうことがあったので、変更点があるときは背景色を変えてわかるようにした。これにより記入内容を保存せずページを離脱してしまい、内容が失われるという悲劇を回避できるようになった。やり方は適当に検索して出てきた Stack Overflow を参考に、ページを読み込んだ時点で JavaScript でフィールド内の要素を JSON.stringify して data attribute に格納し、その後各フィールドの input イベントを監視して変更があるかどうかをチェックしている。
class FormObserver {
constructor() {
this.initializeFields();
this.observeFieldsChange();
}
initializeFields() {
const fields = Array.from(document.querySelectorAll('div.field'));
for (const field of fields) {
const inputElement = field.querySelector('input[type="text"], textarea, input[type="datetime-local"], select option:checked');
if (inputElement === null) {
continue;
}
field.dataset.serialize = JSON.stringify(inputElement.value);
}
}
observeFieldsChange() {
const fields = Array.from(document.querySelectorAll('div.field'));
for (const field of fields) {
const inputElement = field.querySelector('input[type="text"], textarea, input[type="datetime-local"], select');
if (inputElement === null) {
continue;
}
inputElement.addEventListener('input', () => {
if (field.dataset.serialize != JSON.stringify(inputElement.value)) {
inputElement.dataset.changed = 'true';
field.classList.add('edited');
} else {
inputElement.dataset.changed = 'false';
field.classList.remove('edited');
}
})
}
}
}input イベントを監視すると動作がもっさりするのではないかと心配したが、そんなことはないようだ。普通に使えている。
いまのところ管理画面の HTML レンダリングはサーバーサイドで Ruby で行っているが、これ以上凝ったことをやるなら React などを使って JavaScript で HTML を組み立てる方式にしていく方が効率が良さそうだ。