Rust 製の全文検索システム Tantivy を Ruby から使える Tantiny を導入したことを書いた。
結構手軽に使えるのだがやはり日本語のトークナイズ(形態素解析)ができないのでいまいちなところがあった。 Tantivy には lindera-tantivy というものがあって、 Lindera は kuromoji のポートなので、これを使うと日本語や中国語、韓国語の形態素解析ができる。 Tantiny に導入できないか試してみたが、自分の Rust 力では到底無理だった。
ちなみに関連記事の表示でも日本語の形態素解析は行っている。
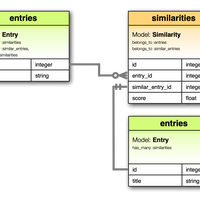
MeCab に neologd/mecab-ipadic-neologd を組み合わせてナウな日本語に対応させつつ形態素解析している。
この仕組みを作ってトークナイズは Ruby で自前で行い、 Tantiny および Tantivy にはトークナイズ済みの配列を食わせるだけにした( Tantiny はトークナイズ済みのテキストを受け付けることもできる)。トークナイズを自前で行うことで辞書ファイルで拾いきれないような固有名詞もカバーできる。例えば 山と道 なんかは MeCab と mecab-ipadic-neologd にトークナイズさせると 山 と 道 に分割されてしまう。自前のトークナイザーで単語として認識させていている。おかげで「山と道」をちゃんと検索できるようになっている。
なお、自前のトークナイザーはこんなコードになっている。
class Tokenizer
attr_reader :text
class << self
def run(text)
self.new(text).tokenize
end
end
def initialize(text)
@text = text
end
def cleansed_text
@cleansed_ ||= text.
gsub(/<.+?>/, '').
gsub(/!?\[(.+)?\].+?\)/, '\1').
gsub(%r{(?:```|<code>)(.+?)(?:```|</code>)}m, '\1')
end
def words_to_ignore
@words_to_ignore ||= %w[
これ こと とき よう そう やつ とこ ところ 用 もの はず みたい たち いま 後 確か 中 気 方
頃 上 先 点 前 一 内 lt gt ここ なか どこ まま わけ ため 的 それ あと
]
end
def preserved_words
@preserved_words ||= %w[
山と道 ハイキング 縦走 散歩 プログラミング はてブ 鐘撞山 散財 はてなブックマーク はてな
]
end
def nm
require 'natto'
@nm ||= Natto::MeCab.new
end
def words
@words ||= []
end
def tokenize
preserved_words.each do |word|
words << word if cleansed_text.match?(word)
end
nm.parse(cleansed_text) do |n|
next unless n.feature.match?(/名詞/)
next if n.feature.match?(/(サ変接続|数)/)
next if n.surface.match?(/\A([a-z][0-9]|\p{hiragana}|\p{katakana})\Z/i)
next if words_to_ignore.include?(n.surface)
words << n.surface
end
words
end
endpreserved_words が手製の辞書だ。 はてな や はてブ も辞書登録しておかないと MeCab だとバラバラに分割されてしまって検索できなかった。
難点としては記事更新後に自動でインデックスの更新が行われず、 cron によるバッチ処理でインデックス更新を行っている[1]。なので検索インデックスにデータが反映されるまでにタイムラグがある。 Tantiny でやれれば記事作成・更新時のコールバックとして処理できるのでリアルタイムに変更を検索インデックスに反映させることができるが、個人の日記なのでタイムラグありでも大きな問題にはならない。
本当は Tantiny で lindera-tantivy を使えるようにして Pull Request がカッチョイイのだが、とりあえずは自分は目的が達成できたので満足してしまった。 5 年くらい前から Rust 勉強したいと思っているが、いつまでも経っても Rust を書けるようにはならない。
[1]: mecab-ipadic-neologd を VPS 上でインストールできず(めっちゃメモリを使う)、手元の Mac で Docker コンテナ化して Docker Hub 経由でコンテナイメージを Pull して VPS 上で Docker 経由で動かしている(その辺について書いてる記事: ブログのコンテナ化を試みたけどやめた)