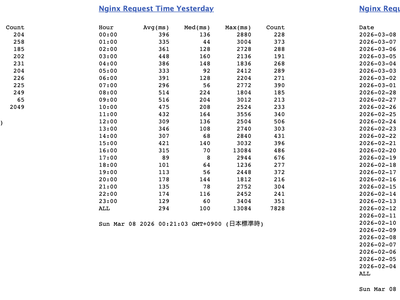
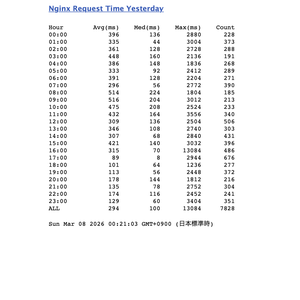
サーバーのディスク容量拡張に失敗
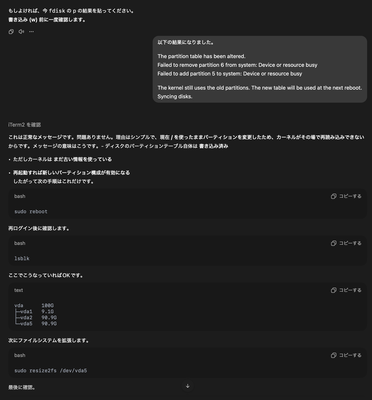
サーバーのディスク拡張作業中にパーティション操作で開始セクターをずらしてしまいUbuntuが起動不能に。ChatGPTの誤った指示で救済手段が見つからず、結局再インストールして復旧。AIの助言には注意が必要だと痛感した。

インターネットユーザー @morygonzalez のブログ。
ブログを書くこと、プログラミング、インターネット、 Mac の便利なソフトウェア、ブラック企業での就労体験、見た映画や読んだ本の感想、カメラ( Nikon Z6 )や iPhone で撮った写真、登山やランニングについて、その他の雑記などを雑多に書いています。
もっと詳しくは About をご覧下さい。