インターネットトレラン

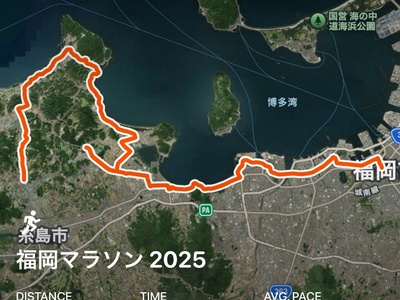
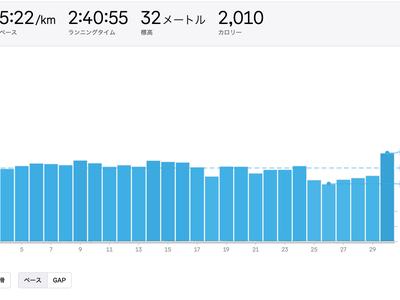
前職で関わったnagayamaとはてなOBのnmyと雷山〜井原山をトレランで縦走。紅葉が美しく、インターネット越しの交流が現実の山で繋がる不思議さを実感。下山後は居酒屋でインターネットの変化やマネジメントの話で盛り上がる。

インターネットユーザー @morygonzalez のブログ。
ブログを書くこと、プログラミング、インターネット、 Mac の便利なソフトウェア、ブラック企業での就労体験、見た映画や読んだ本の感想、カメラ( Nikon Z6 )や iPhone で撮った写真、登山やランニングについて、その他の雑記などを雑多に書いています。
もっと詳しくは About をご覧下さい。