※絵といっても絵画のことではないてす。 UML とかのことです。
夜中まで訳の分からない仕様書・設計書を書かせられてたブラック企業時代の体験が辛すぎて UML 的なやつを見ると嫌な思い出がフラッシュバックしてたけど、最近は絵を描くのが好きになってきて、結構いいものだと思うようになってきた。
当時はアホにみたいにドキュメント書かせられてた。フローチャート、ユースケース図、シーケンス図、 ER 図、画面詳細設計書などなど。もちろん方眼の Excel で( Visio は下っ端には使わせてもらえなかった)。オープンソースのショッピングカート( Magento )のガワだけ変えて EC サイト構築する場合でもユースケース図描けとか言われて、 OSS のコードの処理の流れを図化するとかギャグだろと思ってた。要するに単なる工数稼ぎで客から金を詐取するための汚いやり口だったのだ。
そもそも実際に絵に描いた通りにシステムを作れることなんてなかった。複数社で引き継がれてきたコ〜ルドフュ〜ジョンのコピペコードの塊の前では UML とか描いても意味なかったし、自分たちのコーディングスキルも低かった。今でも事前に絵に描いた通りにシステムを作るのは難しいと思う。
しかし自社で製品を作ってる会社で働くようになって、自分たちのために描くシーケンス図やらフローチャートはとても役に立つなと思うようになった。実装前にドキュメント作るよりも、実装してて詰まったときや最初にガーっと作ったやつをリファクタリングしてるとき、開発終盤のコードが安定してきたときに作るととてもよい。
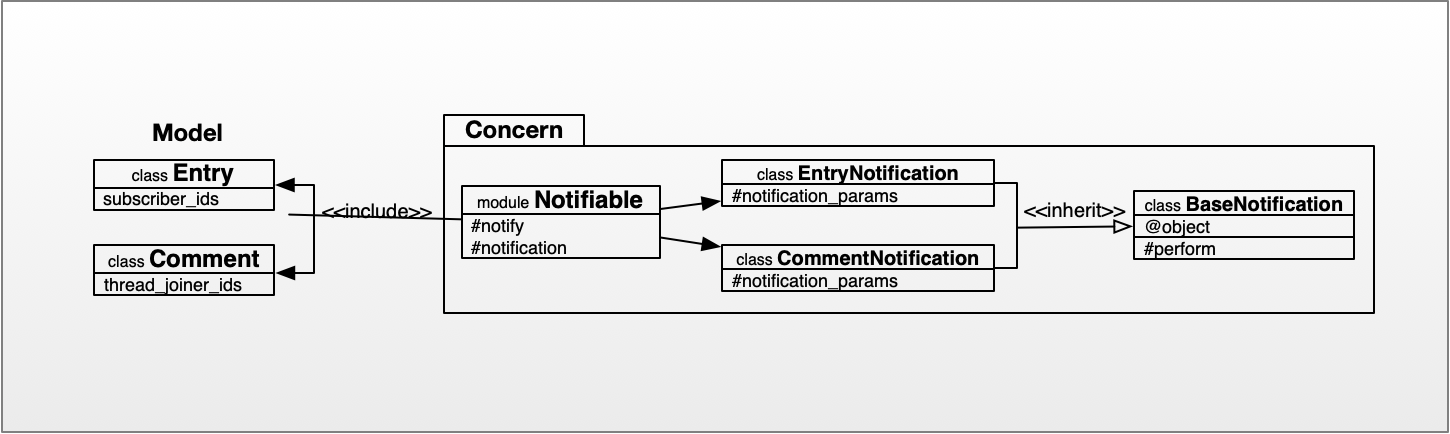
最近気に入ってるのはシーケンス図で、 Microservice 化されたウェブアプリケーションのデータの流れを理解するのにとても役に立つ。社内のドキュメントツールを Kibela にしたおかげで PlantUML が使えるのが快適極まりない。 Markdown なので変更があったときに絵をサクッと編集しやすい。これがドローツールをいちいち起動して編集したあと画像を書き出さないといけないとかだったらなかなか更新する気にならない。
とはいえ PlantUML が苦手なやつもあって、フローチャートはダメダメだった。フローチャート、プログラムの処理の流れが描いてあるだけでは不十分で、見た目の整い具合も重要だと思う。そもそも絵や図は言葉で書かれているものだと理解しづらいものを視覚化して理解しやすくするものなので見た目はとても重要になる。 PlantUML ではなかなか条件分岐や処理の塊の位置が揃わず、綺麗にグリッドに配置される OmniGraffle の方が圧倒的に描きやすかった。 OmniGraffle は値段が高いのが玉に瑕だけどとても良いものだと思う。
頑張って PlantUML でフローチャート描いたけど全然きれいにならなくて、 OmniGraffle で描いたら 5 分くらいできれいなやつ描けてやっぱり絵を描くならネイティブのドローツールに限るなと思った。 pic.twitter.com/i77JeDvDUn
— morygonzalez (@morygonzalez) February 27, 2018
ブラック企業時代は絵を描くことが金儲けのためだから辛かったのだと思う。自分たちが後から困らないようにするために書くドキュメントは全然つらくない。当事者意識を持てるか持てないかの違いなのだと思う。 ATI を高めていけば Excel 方眼シートも辛くないのかも知れない。知らないけど。