404 ページ、昔はそもそもなくて 404 Not Found ステータスを返すだけだったり、あっても「見つかりません」というだけのものが多かったけど、最近はサイトマップ的なコンテンツや代替となるコンテンツを表示するサイトも見かける。というわけでこのサイトでもやってみることにした。
このブログの URL は /YYYY/MM/DD/slug という形式になっている。パスの /YYYY/MM/DD の部分はお飾りで、実際は slug がユニークになっているので slug で表示すべき記事を判定している。
よくあるのが記事を公開後、 slug 部分にタイポを見つけて変更するというケース。しかしすでにその時点で記事が Twitter などでバズってたりすると、 Twitter で共有されている記事を見てやってきた人が 404 Not Found ページを見ることになる(この前の「不便になるインターネット」がまさにそうだった)。それはまずいので slug のタイポを修正すると同時に Nginx の設定ファイルをいじってタイポ修正前の URL から修正後の URL へリダイレクトするようにしていた。しかしリダイレクトごときでサーバーの設定ファイルを修正して root 権限でリロードするというのはめんどい。 SSH でログインもしなければならない。大げさすぎる。
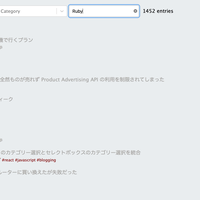
というわけで思いついたのがこの機能で、 Ruby でクラス名やメソッド名をタイポしたときに正しい候補を表示する did_you_mean.gem を利用した。存在しない slug で URL を開くと以下のように候補が表示される。

コードはこんな感じ。
# Helper
def not_found_candidates
@not_found_candidates ||=
begin
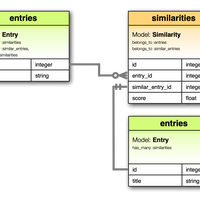
slugs = Entry.published.where.not('slug REGEXP ?', '^[0-9]+$').pluck(:slug)
spell_checker = DidYouMean::SpellChecker.new(dictionary: slugs)
current_slug = request.path_info.split('/').last
slug_candidate = spell_checker.correct(current_slug)
Entry.published.where(slug: slug_candidate)
end
end
# View
- if not_found_candidates.any?
%p Did you mean?
- not_found_candidates.each do |candidate|
= link_to candidate.title, candidate.linkデータベースから slug 一覧を取り出して辞書とし、 DidYouMean::SpellChecker に食わせて似たページの候補を取得して表示する。タイポありのページを訪れた人はワンクリックしなければならないという手間が増えるが、これでタイポを修正したときに面倒なリダイレクトの設定をする必要がなくなった。
なお 404 ページには検索窓や最近の記事、カテゴリー一覧も表示して回遊性を高めている。