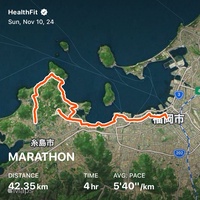
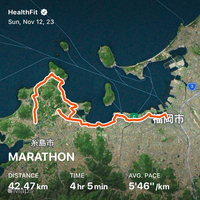
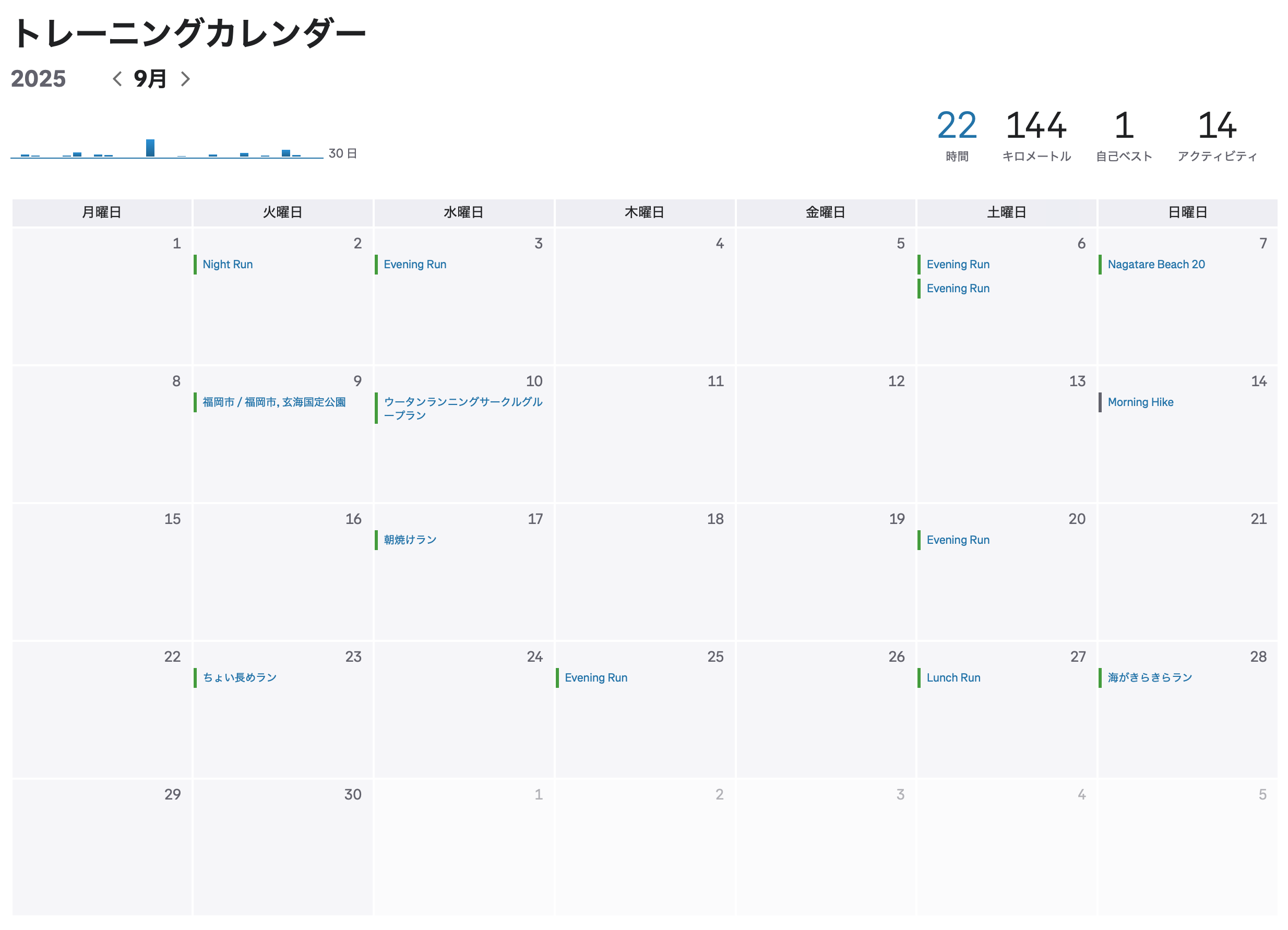
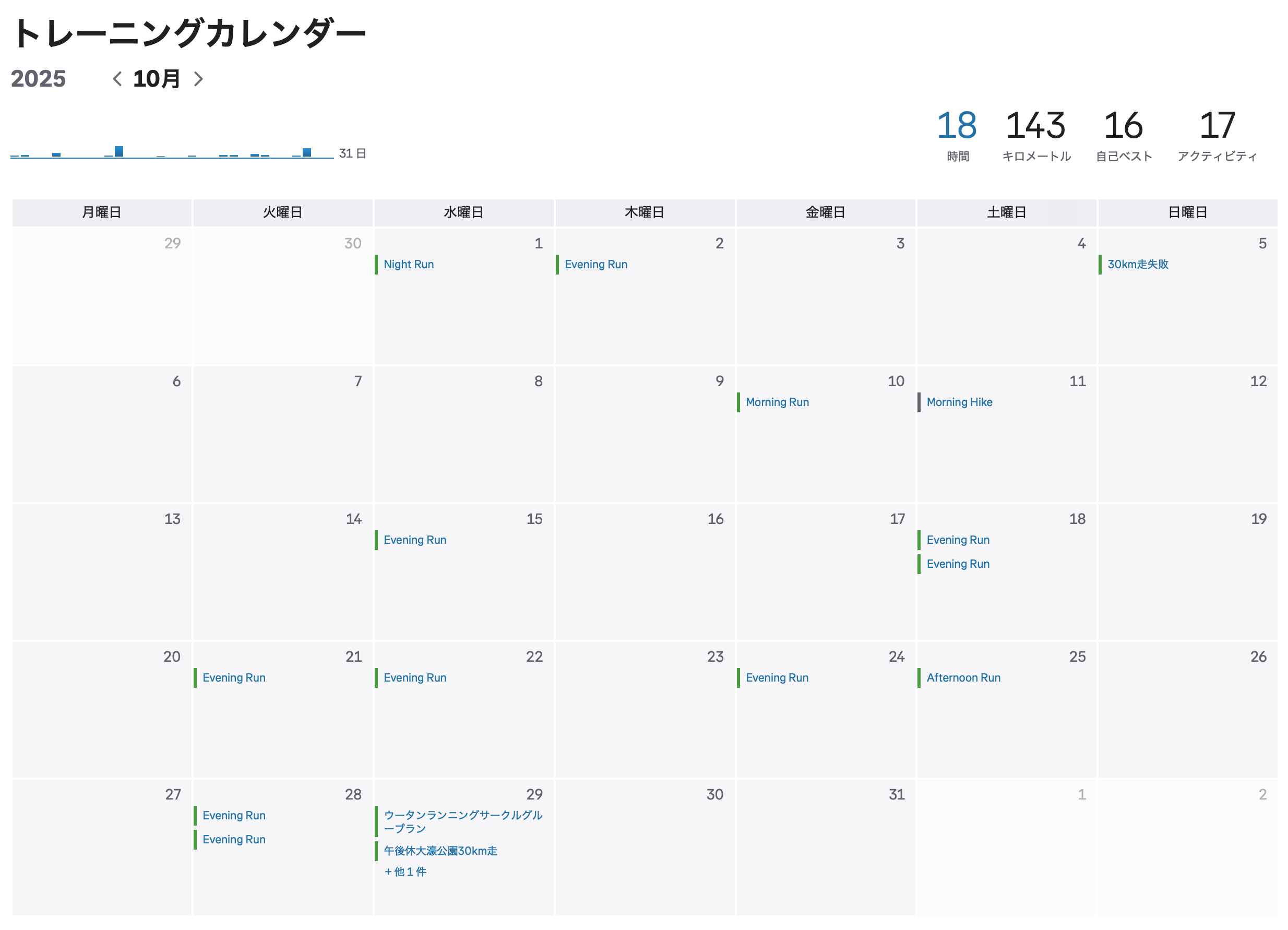
Strava クローンのような機能を Claude Code と Codex を使って二日で作った。 Garmin や COROS や Apple Watch でとった FIT ファイルや GPX ファイルをアップロードすると軌跡とペースを表示してくれるやつ。ソーシャル機能やセグメント、心拍数ゾーン分析などがない簡易的な Strava みたいなやつ。ブログ記事に埋め込める機能もつけた。

AI エージェントやばい、 AI すごい、エンジニアいらなくなるみたいなことが盛んに言われてるけど、自分が直接開発しなくなったのであまりピンと来てなかった。本腰を入れて使ってみて AI 開発の何たるかがわかった気がする。やり方を知っているけどとにかく作業が面倒くさくてできないこと、やり方があることは知っているがやり方自体は知らないこと(勉強しないとできないこと)が、 AI があればどんどん簡単にできるようになった。時間のなさとかやる気のなさ、学習意欲のなさを補ってくれる感じ。
AI エージェント時代のエンジニア、「やり方があることは知っているがやり方自体は知らない」領域がいっぱいある人が強いと思う。「やり方があることは知っているがやり方自体は知らない」と「やり方があるかどうかもわからない」は隣り合っていて、経験が多い人ほど「やり方があるかどうかもわからない」を「やり方があることは知っているがやり方自体は知らない」領域に移してきているので AI を使った開発で有利になる。つまりおっさんエンジニアほど有利になる。
実装力は AI で差別化ポイントではなくなるので、 AI が出してくるものの善し悪しを判断できるセンスとか、これまでこれまでソフトウェア開発でハマった経験とか、そういうのも重要になる。やっぱりおっさんの方が有利。
News Picks の週刊ジョーホーで、若手ほど新しいテクノロジーで不利になるこれまでになかった時代がやってくると言ってたけど(22:11〜)、その通りだと思った。

アメリカで若手エンジニアの採用を減らしているというのはむべなるかな。
ただしおっさんなら無条件で安泰というわけではなくて、「やり方があるかどうかもわからない」を「やり方があることは知っているがやり方自体は知らない」領域に移していける力は問われつづけると思うので、おっさんになっても「やり方があることは知っているがやり方自体は知らない」領域が狭い人や、この領域を広げる努力を怠っている人は市場価値がなくなっていくと思う。




























![[番外編 #12] mixiのV字回復はここから!朝倉祐介に訊く逆転のヒント - ハイパー起業ラジオ](https://portalshit.net/imageproxy/200/https://image.listen.style/img/zgHpjWKb1OuJ4iGrrupeHWLNZRTxzIQz3IPGfJvFkVo/resize:fill:1200:1200/aHR0cHM6Ly9kM3Qzb3pmdG1kbWgzaS5jbG91ZGZyb250Lm5ldC9zdGFnaW5nL3BvZGNhc3RfdXBsb2FkZWRfbm9sb2dvLzM5Njk0OTgzLzM5Njk0OTgzLTE3MDAwNjM5ODI3MDYtZTBkY2RkZTIxNGMwNS5qcGc.jpg)