年が明けてからやるのはどうかと思うが、タイミングがなかったので今さらながら 2022 年のふりかえり。
ランニング
2022 年はよく走った。これまでも何度か走ってると書いていたが、ちゃんとグラフにしてみると 2022 年の 8 月までは大して走っておらず、 2022 年の 9 月から本腰を入れて走るようになったようだ。

オレンジ色の線が 2022 年のもので、9 月から傾きが急になっている。 9 月は月間 110km 走った。月間 100km はフルマラソンに出られる基準のようなのでこの頃は調子こいていた。
ランニングの頻度を上げるのに役立ったのが計画表だった。それまで漫然と走っていたが、漫然と走っていると月間 100km も走れないことに気がついた。自分は一回 5km 走っているが、それを気が向いたときに週 2, 3 度やるだけだと月間 50km くらいにしかならない。きちんとランニングした日と距離を確認していかないと目標には辿り着かない。ログは Apple Watch で取得しているが、統計データとしては見られない。なので HealthFit というアプリを使っているが、 HealthFit では目標設定ができないので Numbers でシートを作って管理することにした。これは元はてなのディレクターの二宮さんの記事の真似。
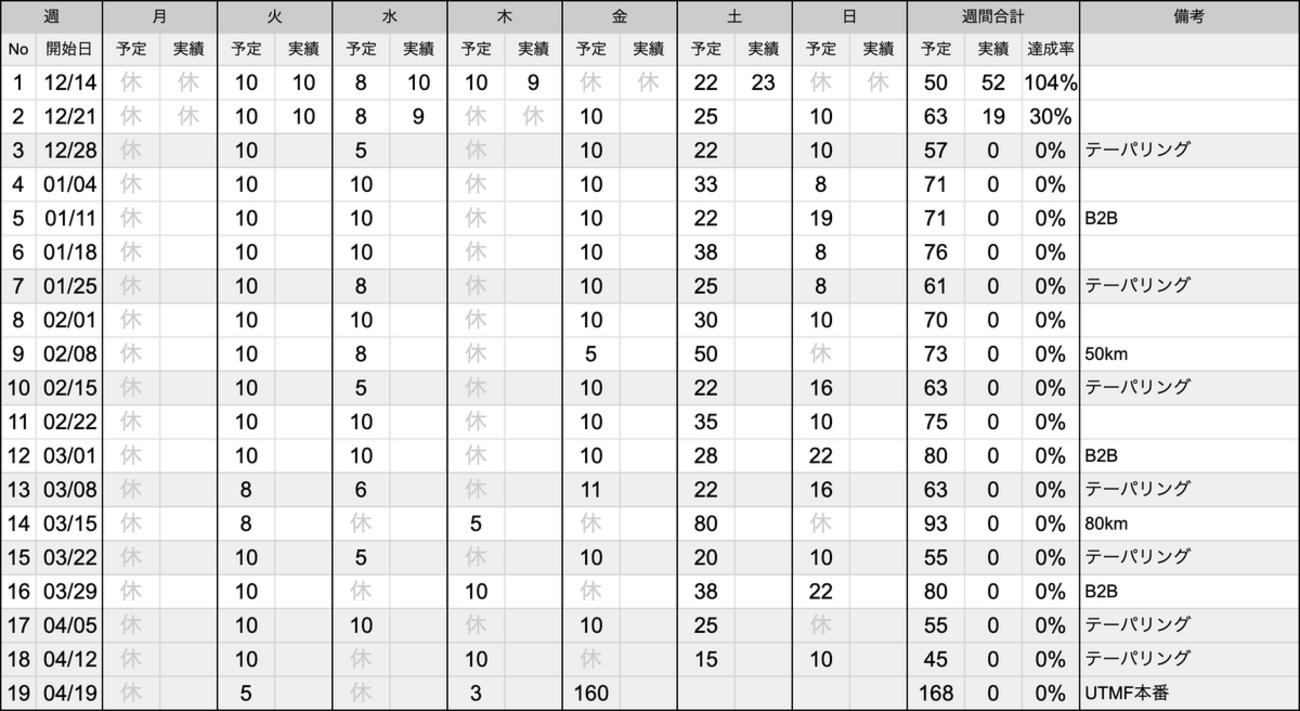
こちらが年間の週次のランニング計画。

こちらが月間の日次のランニング計画。

月間のシートに日次の目標と実績値を入れると、年間の週次のシートに自動反映される仕組みになってる。これによって自分は一週間に何 km 走る予定で現在目標に対してどのくらい達成しているのかを確認できるようになる。
37signals の本を読んで、計画を立てるのはアホだ、数値目標なんて意味がない、未来を先読みすることはできない、という発想に影響されて計画を立てたりするのは何となく良い印象を持っていなかったけど、月間何キロくらい走りたいとか、ベンチマークとなる具体的な数値目標がないとなかなか実績は積み上がっていかないと思う。もちろんまだ走ったことがない状態でいきなり月間 100km のような目標を立てるのは愚かだと思うが、そこそこ走れるようになってきたら(自分の力がわかるようになってきたら)計画を立てたり数値目標を設定したりするのは悪くないことだと思う。
9 月にがむしゃらに走ったおかげか、最近は走るペースが一段速くなっていて、 1km を 5 分台で走れるようになってきた。今年はちょっと色気を出して初心者向けのトレランの大会に出てみようかと思ってる。
登山
4 月に脊振山系全山縦走、 11 月に九州脊梁に行った。夏に北アルプスを予定していたが、ちょうどコロナにかかって行くことができなかった。何にせよ最近は山に登るのよりも近所を走る方が楽しいので山への足が遠のいた一年だった。登山時の体力作りで走り始めたのに本末転倒している。
仕事
一昨年は結構でかい成果を出せたが 2022 年はぱっとしない一年だった。反省したい。
生活
iPhone を買い換えて 11 から 14 Pro になった。カメラが三つになって望遠の写真を撮れるようになったのが便利。 Dynamic Island も便利。タイマーかけてるときに常に Dynamic Island で残り時間を確認できるのは相当便利。 164800 円払ってよかった( 36 回ローン)。
サウナにハマってぼちぼち行っていた。サウナーの人たちのように一週間に何回も通うというほどではないが、金曜日の仕事帰りにサウナまで走って行ってサウナに入って帰るというのを何回かやった。花金感が出て良い。
2020 年に車を買い換えたがあまりドライブしてない。アメ車なので燃費が悪い、コロナなので出かけづらい、などいろいろあるが、せっかく車を買い換えたのに使わないで置物になってるのはもったいないので有効活用したい。
そういえば 2022 年は YouTube をよく見た。 YouTube Premium に入ったので広告が表示されなくなり、邪魔が入ることなくとてもなめらかに動画を視聴できるようになった。 Netflix はあまり見ていなかったので解約し、 YouTube で素人が上げる動画をよく見た。ストーリーのない、ただ料理をしているだけとか、ただ穴蔵を掘っているだけの 15 分くらいの動画を見るのがちょうどよい。 Netflix の動画は長いし、ことあるごとに金、暴力、セックスを意識させられるので見るのがきつい。こってりしすぎている。
ブログ
Tantivy を導入して全文検索できるようにした。検索も見た目を変えてインクリメンタルサーチできるようにしたりした。年に一回くらいはバズる記事を書きたいが、 2022 年は不作だった。反省したい。
総括
仕事や生活、ブログは本当にぱっとしなかった。その代わり走ることを頑張っているのかも知れない。ランニングや登山は、大して頑張って生きていないのに走ったり山に登ったりするとめっちゃ頑張ってるかのような錯覚を得られて自己肯定感が高まる。仕事などでもちゃんと成果を出しつつ走ったりできたら良いのだけど自分の場合は逃避になってるような気がする。しかし走るのをやめたら仕事で成果を出せるかというとそうでもないし、遺伝的に糖尿病のリスクがあるので発症しないように死ぬまで走り続けるしかない。 2023 年は運動しつつ仕事やブログ書きでも一定の成果を上げたい。あともうちょいサウナに行きたい